
Paper Review - Class Activation Map
이 포스트에서는 2016년 CVPR에 실린 “Learning Deep Features for Discriminative Localization”의 Visualization 방법인 CAM(Class Activation Map)에 대해서 살펴보겠습니다.
Key Point
- Weakly-supervised Learning for Object Localization
- Visualize class discriminative features
2012년 ImageNet 데이터 셋을 이용한 대회인 ILSVRC에 CNN을 이용한 AlexNet이 우승한 이후, CNN에 대한 연구가 활발히 이루어지고 있습니다.
CNN의 발전 경향을 살펴보면 2012~2015년 사이에는 마지막 레이어로 Fully-connected layer를 사용하지만, 2015년 GoogLeNet에서 GAP(Global Average Pooling) layer를 사용한 이래로, 최근까지 등장하고 있는 새로운 CNN 아키텍쳐들은 마지막 layer에서 fc layer가 아닌 GAP layer를 사용하고 있습니다. 이유가 무엇일까요?
fc layer는 연산량 관점에서는 도입하기에 비용이 큰 layer 입니다. 말 그대로 Fully-connected 되어있기 때문에 Convolution layer와 비교해서도 당연히 연산에 필요한 파라미터가 많아 과적합(overfitting)되기 싶습니다.
또한, 논문 [2]에 따르면, CNN의 Convolutional unit들은 개체의 위치 정보를 보유하고 있지만, fc layer를 거침에 따라 이러한 위치 정보가 손실된다는 것을 확인했습니다.
이러한 fc layer의 여러가지 단점들을 해소하기 위해, 최근 등장하고 있는 CNN 아키텍처(GoogLeNet.2015, ResNet.2016, Xception. 2017 …)들은 마지막 layer로 fc layer대신 GAP layer를 사용하고 있습니다.
GAP(Global Average Pooling)와 GMP(Global Max Pooling)
그렇다면, GAP layer는 무엇일까요?
영문 이름에서 알 수 있듯이, 전역적으로(Global) Average Pooling을 수행하는 layer 입니다.
또한, 일반적인 pooling layer가 max 연산을 가지고 있듯이, GMP(Global Max Pooling)도 있습니다. 마찬가지로, 전역적으로 Max Pooling을 수행하는 layer를 의미합니다.
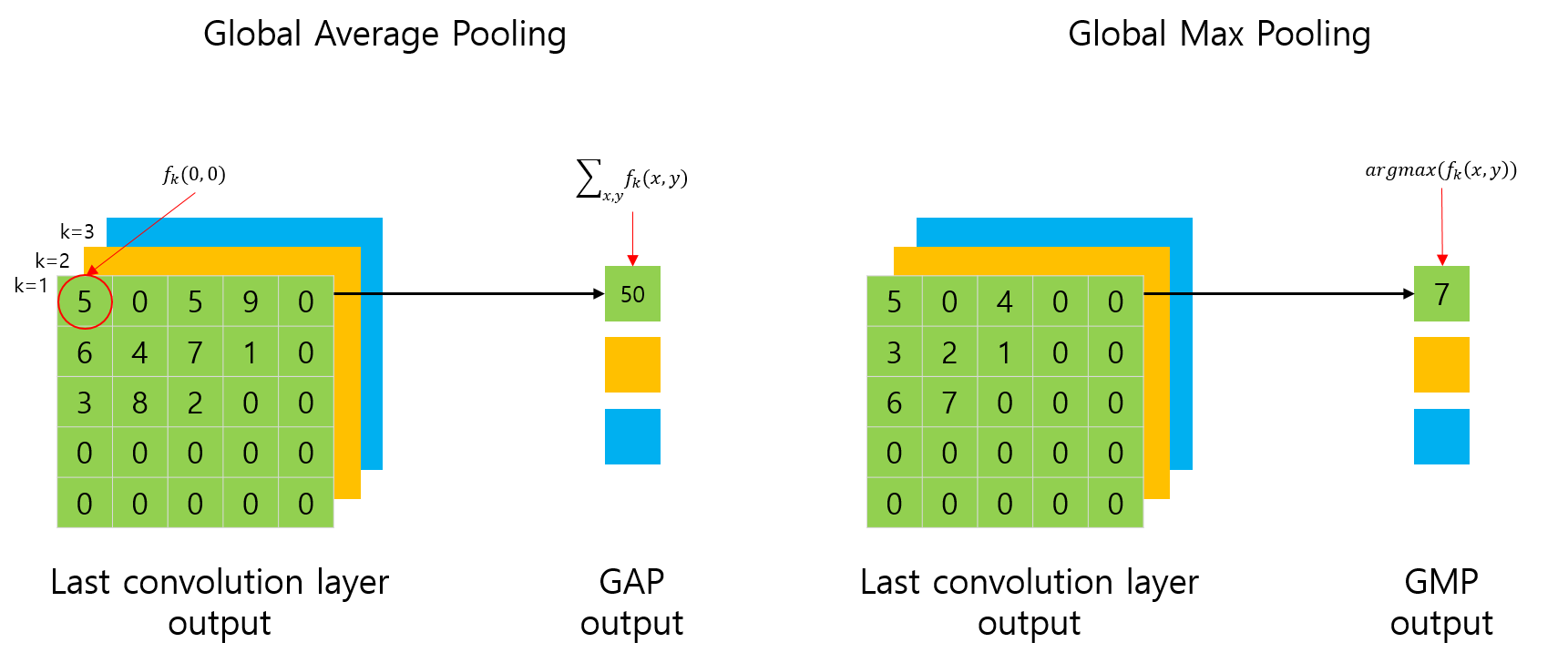
위 그림에서 좌측이 GAP를 표현한 그림이고, 우측이 GMP를 표현한 그림입니다.
사실, GAP 연산은 평균(Average)을 취해야 하는게 맞지만, 논문에서 표현한 수식과 혼동하지 않기 위해서 평균값을 취하지 않았습니다.
그림에서 표현된 것처럼 \(f_k(0,0)\)은 CNN의 feature map의 0,0 번째에 해당하는 요소의 값을 의미합니다.
GAP나 GMP의 연산 결과는 그림과 같이 각 채널별로 하나의 값이 나오게 됩니다. 즉, 이전 5x5 feature map의 채널이 3개였다면, feature map의 크기와 상관없이, 채널의 개수에 해당하는 3개의 값(1x1)이 출력됩니다. (당연한 말이죠? 전체에 대해 평균이나 최대값을 취했으니까요.)
이러한 GAP layer는 fc layer와 달리 연산이 필요한 파라미터 수를 크게 줄일 수 있으며, 결과적으로 regularizer와 유사한 동작을 해서 과적합을 방지할 수 있습니다.
fc layer에서는 Convolution layer에서 유지하던 위치 정보가 손실되는 반면, GAP나 GMP layer에서는 유지할 수 있습니다[2].
이번에 다루는 논문에서는 이러한 GAP와 GMP의 특성을 기반으로, 클래스에 따라 CNN이 주목하고 있는 영역이 어떤 부분인지 시각화하는 방법인 CAM(Class Activation Map) 제안하고 있으며, 이러한 시각화 방법은 Object Localization 으로도 활용될 수 있다고 합니다.
즉, 일반적인 Image Classification을 위해 Weakly-supervised로 학습된 CNN으로도 Image Localization을 할 수 있다는 의미입니다. 그럼 Class Activation Map이 무엇인지 살펴봅시다.
What is CAM(Class Activation Map)?
먼저 GAP를 사용하는 CNN 아키텍쳐의 구조를 살펴보면 다음 그림과 같이 요약할 수 있습니다.
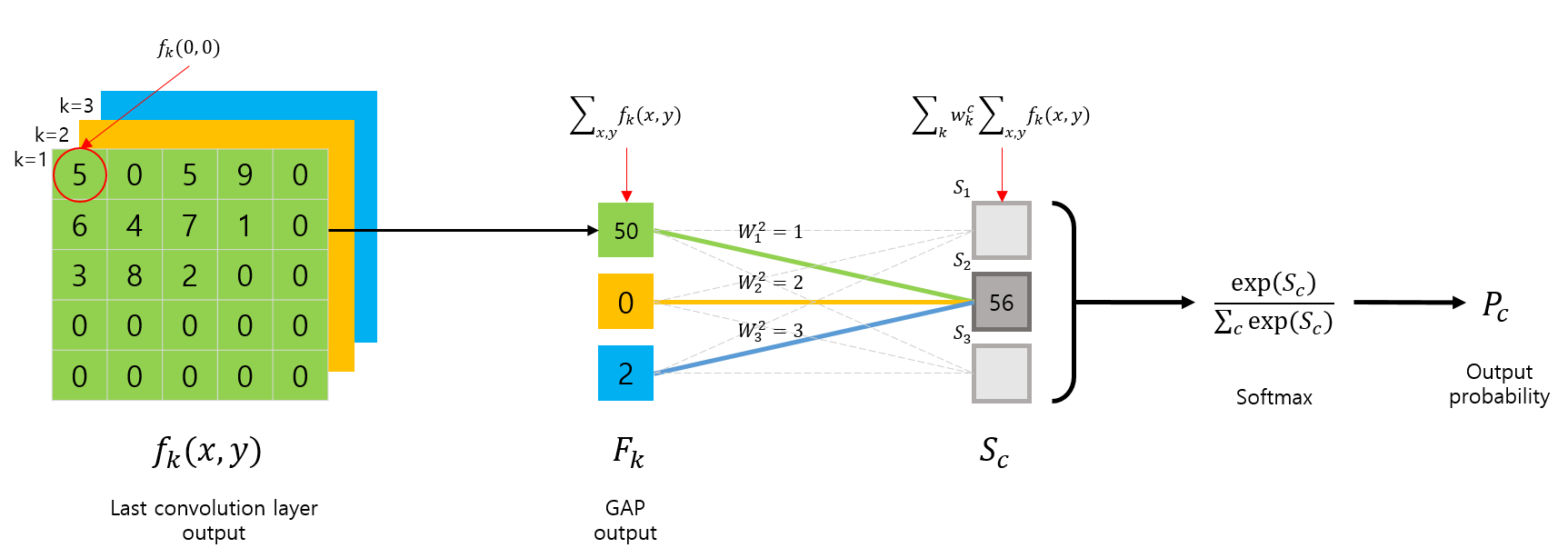
먼저 마지막 Convolution layer 에서 출력된 feature map \(f_k(x,y)\) 는 GAP 연산이 취해지며 k개의 값이 출력됩니다.
\[F_k = \sum_{x,y}f_k(x,y)\]이후 GAP의 출력은 CNN의 마지막 출력 layer인 \(S_c\) 로 전달되면서 linear combination(weighted sum)을 수행합니다.
\[\begin{split} S_c &= \sum_{k}w_k^c F_k \\ &= \sum_{k}w_k^c \sum_{x,y}f_k(x,y) \\ &= \sum_{x,y}\sum_{k}w_k^c f_k(x,y) \end{split}\]이렇게 계산된 \(S_c\)는 Softmax layer를 거처, 최종 출력을 만듭니다.
CAM은 위의 \(S_c\)를 도출하기 위한 수식을 살짝 변경해서, 다음과 수식과 같이 클래스 \(c\) 에 대한 Map 을 구합니다.
\[\begin{split} M_c(x, y) &= \sum_{k}w_k^c f_k(x, y) \end{split}\]위 수식의 도출 과정을 그림으로 표현하면 다음 그림과 같이 표현될 수 있습니다.
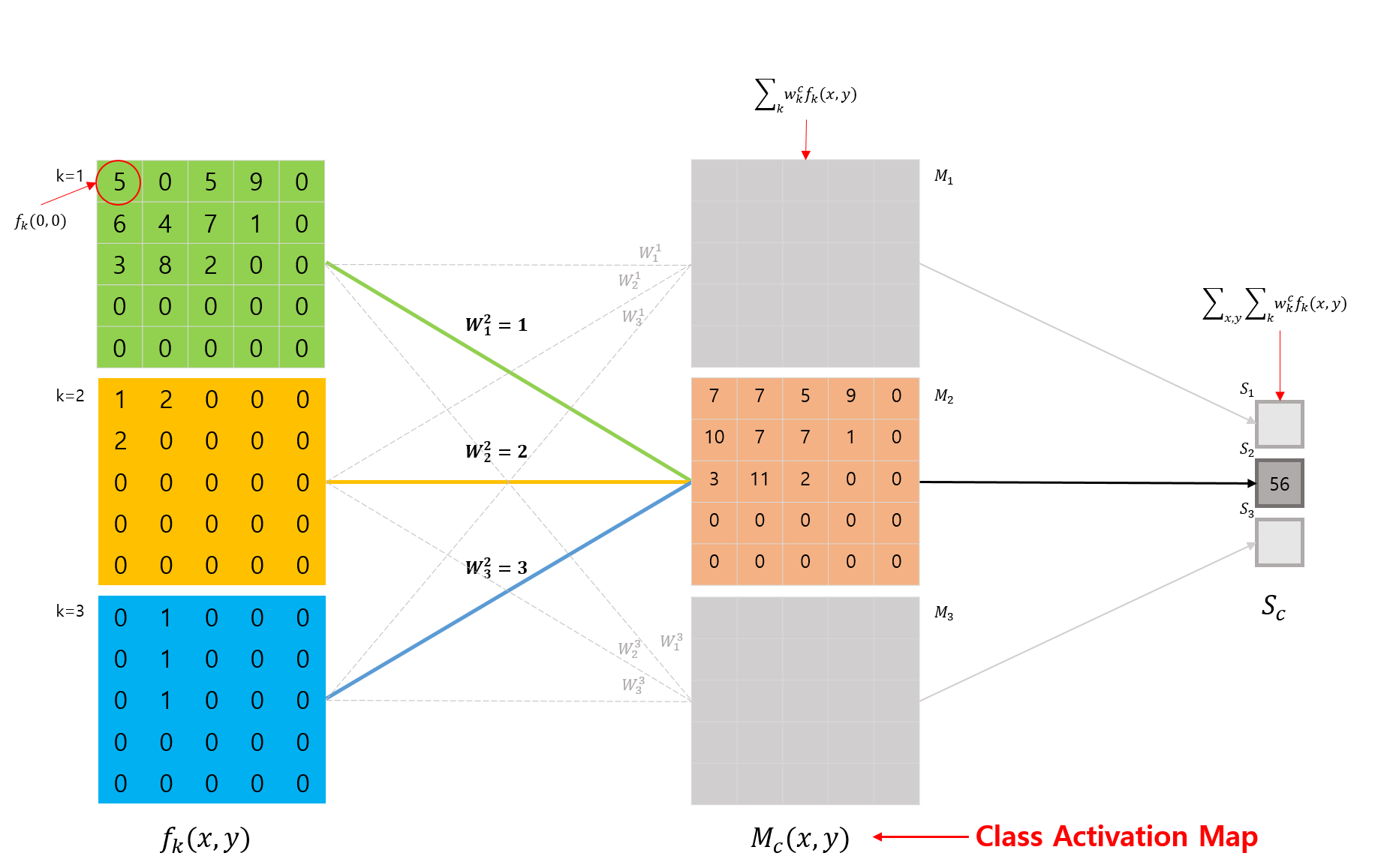
수식을 이해하기 위해 CAM이 어떤 동작을 하는지 다시한번 확인해봅시다.
CAM은 특정 클래스 \(c\) 를 구별하기위해 CNN이 어떤 영역을 주목하고 있는지 시각화하는 방법입니다.
2번째 그림(CNN Architecture with GAP)을 예로 들면, 특정 클래스 \(c = 2\) 를 구별하기 위해 이 클래스에 연결된 weights \(w^2_1, w^2_2, w^2_3\) 와 각 feature map에 대해 linear combination(weighted sum)을 취한 결과가 바로 CAM입니다.
3번째 그림(What is Class Activation Map)을 통해서 확인해보면, \(S_c\) 를 구하는 수식에서, GAP에 사용되었던 feature map에 대한 평균(논문에서는 합)만 제외한 것입니다. (당연히 feature map에 대해 합이나 평균을 취해버리면 시각화를 못하죠? 값이 하나가 되니까..)
이제 keras를 이용해서 CAM을 구현하는 방법에 대해 살펴봅시다.
How to implement CAM?
본 포스트에서 다루는 CAM에 대한 소스코드는 [여기]를 참고하세요.
위 소스코드는 사용의 편의성을 위해서 class로 랩핑해뒀습니다.
그럼 어떻게 CAM을 구현하는지 알아볼까요?
수식을 다시한번 가져와서 코드로 구현해봅시다.
수식을 살펴보면 \(f_k(x, y)\) 가 있습니다. \(f_k(x, y)\)는 마지막 Convolution layer 의 출력 feature map 입니다. 코드로 가져와 봅시다.
model_input = model.input
model_output = model.layers[-1].output
# f_k(x, y) : 마지막 Convolution layer의 출력 feature map
f_k = model.get_layer(last_conv).output
# model의 입력에 대한 마지막 conv layer의 출력(f_k) 계산
get_output = K.function([model_input], [f_k])
[last_conv_output] = get_output([img_tensor])
# batch size가 포함되어 shape가 (1, width, height, k)이므로
# (width, height, k)로 shape 변경
# 여기서 width, height는 마지막 conv layer인 f_k feature map의 width와 height를 의미함
last_conv_output = last_conv_output[0]
여기서 K.function은 keras.backend.function으로, placeholder tensor 리스트와, 모델 그래프내 특정 출력 tensor 리스트를 전달해주면 특정 layer의 출력들을 얻을 수 있는 함수를 반환해줍니다.
자, 우리는 지금 마지막 Convolution layer의 출력인 ‘last_conv_output’을 얻었습니다. 또 무엇이 필요할까요?
수식을 살펴보면 \(w_k^c\) 와의 linear combination(weighted sum) 이 필요하네요. 해당 클래스에 대한 weight들을 가져옵시다.
# 출력(+ softmax) layer와 GAP layer 사이의 weight matrix에서
# class_index에 해당하는 class_weight_k(w^c_k) 계산
# ex) w^2_1, w^2_2, w^2_3, ..., w^2_k
class_weight_k = model.layers[-1].get_weights()[0][:, class_index]
‘class_index’는 특정 클래스 \(c\) 를 의미합니다. 우리가 설정할수도 있고, 일반적으로는 모델이 예측한 클래스 인덱스를 사용합니다.
이제 feature map과 \(w_k^c\)에 대해 linear combination(weighted sum) 를 수행하는 코드를 구현해봅시다.
# 마지막 conv layer의 출력 feature map(last_conv_output)과
# class_index에 해당하는 class_weight_k(w^c_k)를 k에 대응해서 linear combination을 구함
# feature map(last_conv_output)의 (width, height)로 초기화
cam = np.zeros(dtype=np.float32, shape=last_conv_output.shape[0:2])
for k, w in enumerate(class_weight_k):
cam += w * last_conv_output[:, :, k]
CAM 구현이 다 끝났습니다.
하나만 참고할 점은, keras.backend.function() 함수는 모델 그래프 내 특정 레이어들의 출력을 얻기 위한 함수를 만들어준다고 했는데 이 작업은 꾀 시간이 걸리는 작업입니다. 따라서 여러개의 이미지에 대해 CAM을 얻어보고자 할 경우에는 keras.backend.function으로 함수를 만드는 작업을 분리하는게 좋습니다. class로 랩핑한 코드 [keras-CAM]를 참고해보세요.
자, 마지막으로 구현한 코드를 이용해서 cam을 얻어봅시다. 모델은 keras.application에 있는 ResNet50 모델을 사용했습니다.
※ CAM을 얻으려면 CNN의 마지막 Convolution layer와 모델의 출력 layer 사이에 fc layer가 아닌 GAP가 있어야 계산이 가능합니다.
※ 즉, VGG와 같은 아키텍쳐에서 사용하려면, fc layer 2개를 GAP로 대체한 후 다시 학습한 다음에 사용해야 합니다.
img_width = 224
img_height = 224
model = ResNet50(weights='imagenet')
print(model.summary())
img_path = '../images/elephant.jpg'
img = load_image(path=img_path, target_size=(img_width, img_height))
preds = model.predict(img)
predicted_class = preds.argmax(axis=1)[0]
# decode the results into a list of tuples (class, description, probability)
# (one such list for each sample in the batch)
print("predicted top1 class:", predicted_class)
print('Predicted:', decode_predictions(preds, top=1)[0])
# Predicted: [(u'n02504013', u'Indian_elephant', 0.82658225), (u'n01871265', u'tusker', 0.1122357), (u'n02504458', u'African_elephant', 0.061040461)]
cam_generator = CAM(model, activation_layer)
cam = cam_generator.generate(img, predicted_class)
cam = cam / cam.max()
cam = cam * 255
cam = cv2.resize(cam, (img_width, img_height))
cam = np.uint8(cam)
img = cv2.imread(img_path)
img = cv2.resize(img, (img_width, img_height))
cv_cam = cv2.applyColorMap(cam, cv2.COLORMAP_JET)
fin = cv2.addWeighted(cv_cam, 0.7, img, 0.3, 0)
cv2.imshow('cam', cv_cam)
cv2.imshow('image', img)
cv2.imshow('cam on image', fin)
cv2.waitKey()
cv2.destroyAllWindows()
Results
몇가지 이미지에 대해 CAM을 출력한 결과는 다음 그림과 같습니다. 이 결과 이미지를 만드는 코드는 [keras-CAM]의 ‘CAM Visualization.ipynb’ jupyter notebook 파일을 참고하세요.

Additional
지금까지 CAM이 무엇인지 그림과 수식을 통해 살펴보고, keras로 구현도 해봤습니다.
그런데, 마지막 출력 layer 이전에 fc layer를 포함하고 있는 VGG 아키텍쳐와 같이, GAP나 GMP layer가 위치하지 않으면 계산이 불가능하다는 단점이 있습니다.
다음에 살펴볼 논문인 Grad-CAM에서는 이러한 단점을 해결해서 모든 CNN 아키텍쳐에서 CAM을 출력할 수 있는 방법을 소개하고 있습니다.
Source Code
References
[1] Learning Deep Features for Discriminative Localization, 2016 [paper]
[2] Object detectors emerge in deep scene cnns [paper]