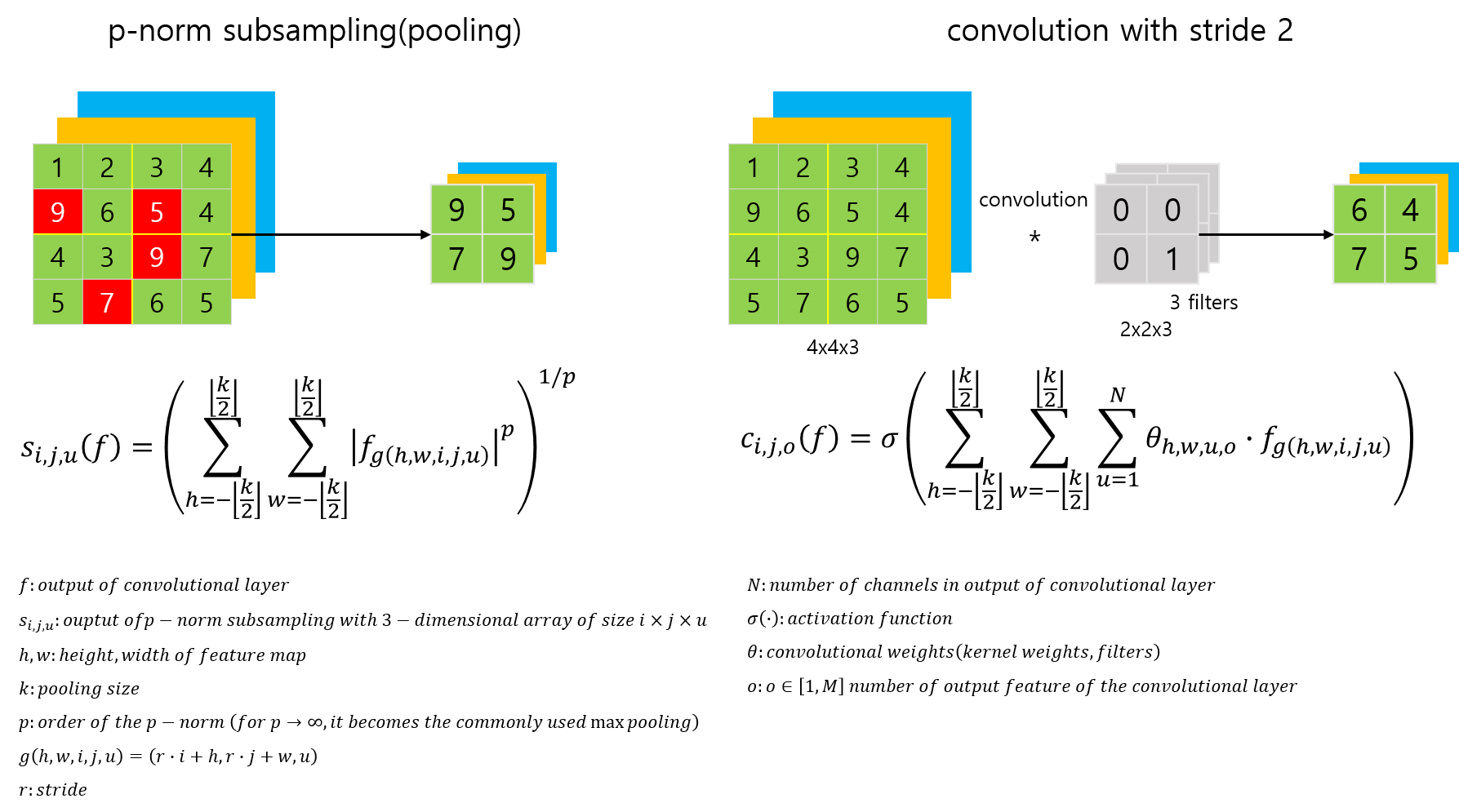이 포스트에서는 2015년 ICLR에 실린 “STRIVING FOR SIMPLICITY: THE ALL CONVOLUTIONAL NET”에 대해서 살펴보겠습니다.
Key Point
max-pooling can simply be replaced by a convolutional layer with increased stride
이 논문에서 주장하는 주된 논점은 “복잡한 activation function 이나 response normalization, max-pooling 연산 없이, Convolutional layer 들로 구성된 CNN도 충분히 좋은 성능을 가지고 있다.” 입니다.
또한, Guided-Backpropagation 이라는 시각화 기법을 제안하면서, backpropagation과 deconvnet 과 비교도 하고 있습니다.
이 포스트에서는 논문에서 제안한 시각화 기법인 Guided-Backpropagation을 조금 더 중점적으로 살펴볼 예정입니다.
pooling and convolution
CNN에서 pooling layer가 사용되는 이유가 무엇일까요? 다음과 같이 정리해볼 수 있을 것 같습니다.
feature들을 좀 더 invariant 하게 만들 수 있음
(spatial dimensionality reduction 을 수행함으로써) 큰 사이즈의 이미지 입력을 허용함
feature-wise pooling은 optimization을 쉽게 만들어줌(?)
그럼 이러한 pooling layer의 단점은 무엇일까요?
pooling을 통해 dimensionality reduction을 수행하면, 일부 feature information이 손실될 수 있음
이 논문에서는 이러한 pooling layer를 convolution layer로 대체하려고 합니다.
pooling layer가 사용되는 가장 중요한 이유 중 하나를 spatial dimensionality reduction 으로 보고, 동일 기능을 하면서 feature information 을 잃지 않는 방식으로말이죠.
교체 방법은 2가지가 있습니다.
CNN에서 각 pooling layer를 제거하고, 이미 있는 convolution layer의 stride를 증가시켜서 연산량 유지
CNN에서 pooling layer를 1보다 큰 stride를 갖는 convolution layer로 교체
즉, 출력 채널과 입력 채널을 갖게 유지하면서, stride로 dimensionality reduction을 수행해서 pooling과 동일한 shape의 출력을 생성하는 convolution layer로 교체
이렇게 구성한 All Convolutional Network가 꾀 효과적인 성능을 보였고,
이 논문에서는 추가로 이렇게 변환한 CNN에 대해 여러 방식의 시각화 기법을 적용했습니다.
이 논문이 발표되기 이전, 2013년도 ZFNet을 연구한 논문에서는, Deconvolution을 이용해서 neuron의 시각화를 했었는데, 이러한 시각화 방식의 큰 단점은 pooling에서 온다고 말하고 있습니다.
즉, deconvnet에서 CNN의 invert를 지원하기 위해서 pooling layer에 switch라는 개념을 도입했는데, 이러한 시각화 기법은 입력 이미지의 상태에 따라 좌지우지되고, 학습된 feature들을 직접적으로 시각화하지 못한다고 합니다.
좀더 디테일하게 정리하자면,
lower layer에는 한정된 양의 invariance를 내포한 일반적인 feature들을 학습하기 때문에, 해당 layer들이 activate하는 단순 패턴들을 reconstruct할 수 있지만,
higher layer에는 비교적 invariant한 표현들을 하기 때문에, 해당 layer의 neuron들을 최대로 activate하는 단일 이미지가 없습니다.(?) 따라서, 좀 더 합리적인 표현을 얻기 위해서는 입력 이미지에 대한 조건(condition)이 필요합니다.
What is Guided-Backpropagation
이 논문에서 제안하는 Guided-Backpropagation에 대한 도식은 다음과 같습니다.
Schematic of visualizing the activations of high layer neurons
— 작성중 —
How to implement Guided-Backpropagation?
본 포스트에서 다루는 Guided-Backpropagation에 대한 소스코드는 [여기]를 참고하세요.
위 소스코드는 논문에서 다루고있는 backpropagation, deconvnet, guided-backpropagation 모두 다루고 있으며, 사용의 편의성을 위해서 class로 랩핑해뒀습니다.
— 작성중 —
Results
몇가지 이미지에 대해 backpropagation, deconvnet, guided-backpropagation으로 시각화한 결과는 다음 그림과 같습니다.
이 결과 이미지를 만드는 코드는 [keras-GuidedBackpropagation]의 ‘GuidedBackprop Visualization.ipynb’ jupyter notebook 파일을 참고하세요.
Results of CAM
Source Code
References
[1] Striving for simplicity: The all convolutional net, 2014 [paper]
이 포스트에서는 2017년 ICCV에 실린 “Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization”의 Visualization 방법인 Grad-CAM에 대해서 살펴보겠습니다.
Key Point
Weakly-supervised Learning for Object Localization
Can apply almost all CNN Architectures
Visualize more detailed class-discriminative feature(Guided Grad-CAM)
이전에 살펴본 CAM(Class Activation Map)논문 리뷰[2]에서는 CAM이 무엇인지 살펴보고 keras로 구현하는 방법에 대해서도 살펴보았습니다.
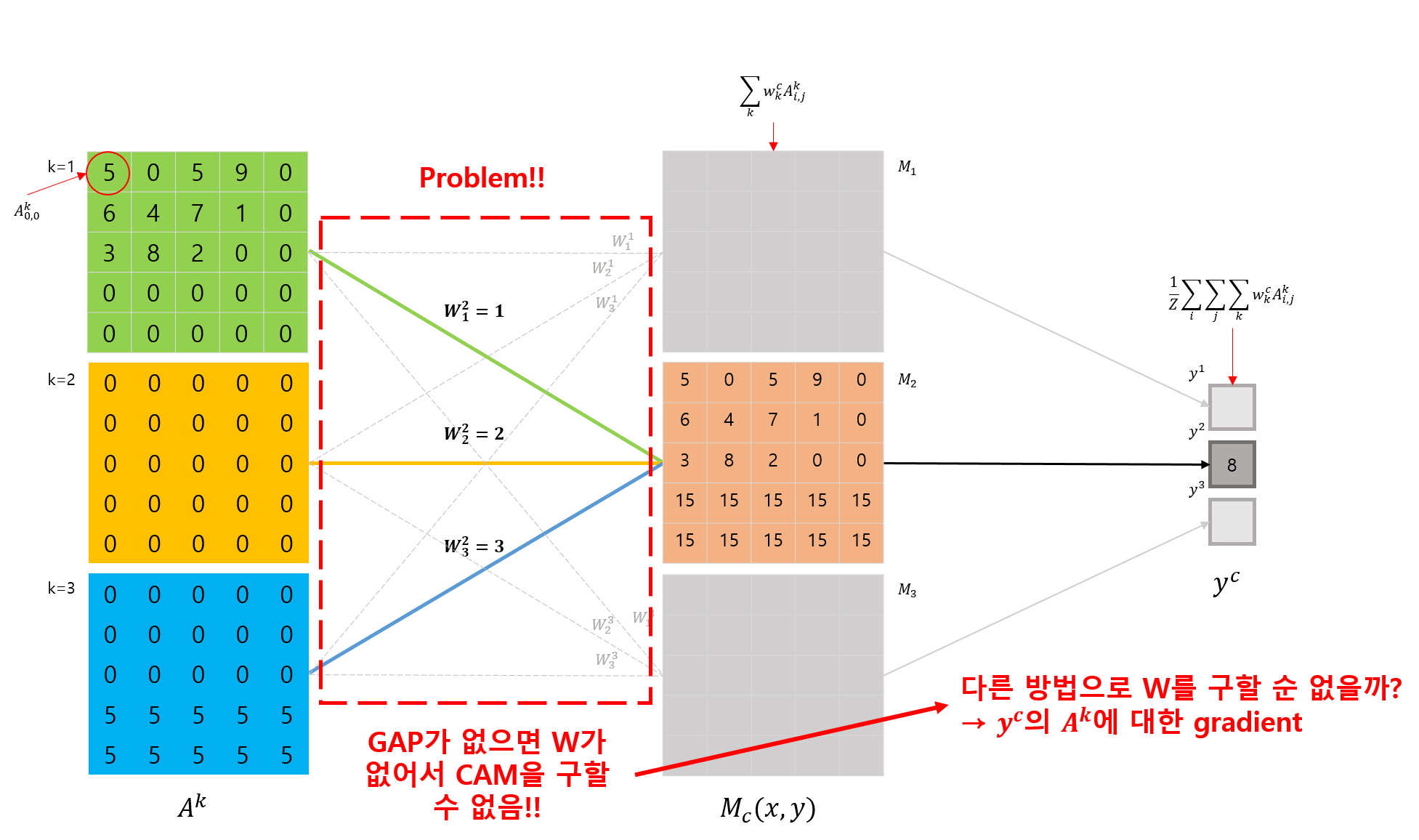
그런데, CAM은 모델의 출력 layer와 마지막 Convolution layer 사이에 무조건 GAP나 GMP layer가 위치해야 CAM을 얻기위한 연산이 가능하다는 큰 단점이 있었습니다.
이번 Grad-CAM[1] 논문에서는 이러한 단점을 해결해서 거의 모든 CNN 모델에 적용이 가능하다는 장점을 가지고 있습니다.
논문에서 Grad-CAM을 적용한 CNN 모델들은 다음과 같습니다.
Fully-connected layer를 사용하는 CNN 모델
Image Captioning과 같은 구조화된 출력을 사용하는 CNN 모델
Multi-modal input을 사용하는 CNN(VQA)
reinforcement learning
또한 Grad-CAM 논문에서는 Grad-CAM과 Guided Backpropagation 통해 얻은 pixel-space gradient와 같은 fine-grained importance를 융합해서 class-discriminative 하면서도, CNN이 주목하고 있는 세세한 부분을 시각화하는 방법을 제안하고 있습니다.
그럼 Grad-CAM이 무엇인지 살펴봅시다.
What is Grad-CAM
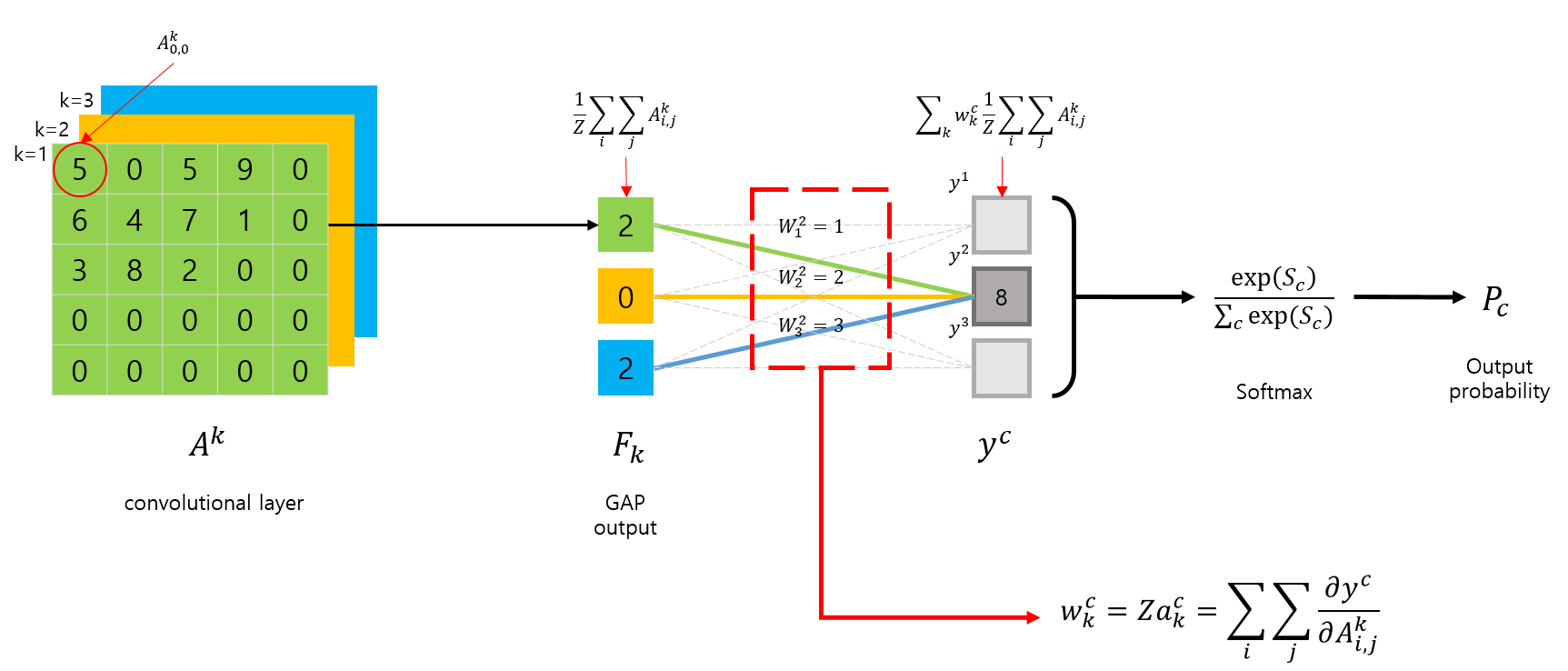
Grad-CAM과 CAM은 CNN모델이 GAP layer를 사용한다는 가정하에는 서로 동일한 동작을 합니다. 그런대 Grad-CAM은 CAM에서 GAP를 사용하는 단점을 해결한다고 언급했죠.
Grad-CAM에서는 GAP와의 연관성을 이용해서 CAM을 구하는 것이 아닌, gradient를 이용해서 CAM을 구한다는 차별점이 있습니다.
Motivation of Grad-CAM
어떻게 Grad-CAM을 구하는지 알아보기에 앞서, GAP와 GMP에 대해 다시 살펴봅시다.
이전 포스트에서는 논문[2]에서 표현된 수식과의 혼동일 피하기위해 GAP를 합으로 표현했지만, 이번에는 원래 GAP의 수식대로 표현해봅시다.
Global Average Pooling & Global Max Pooling
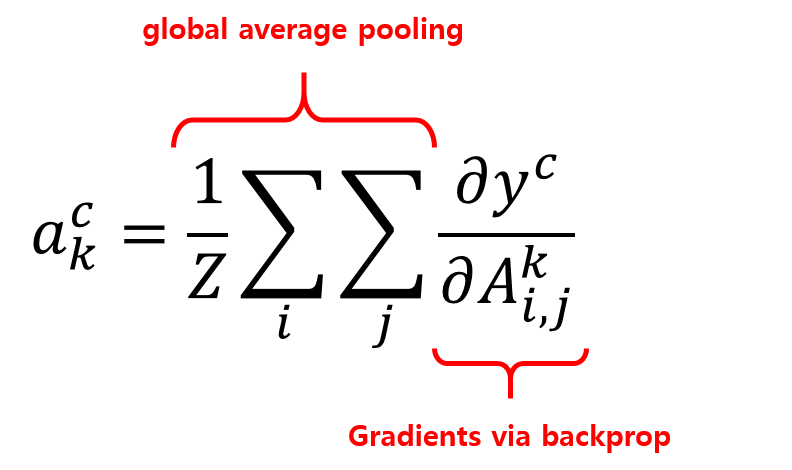
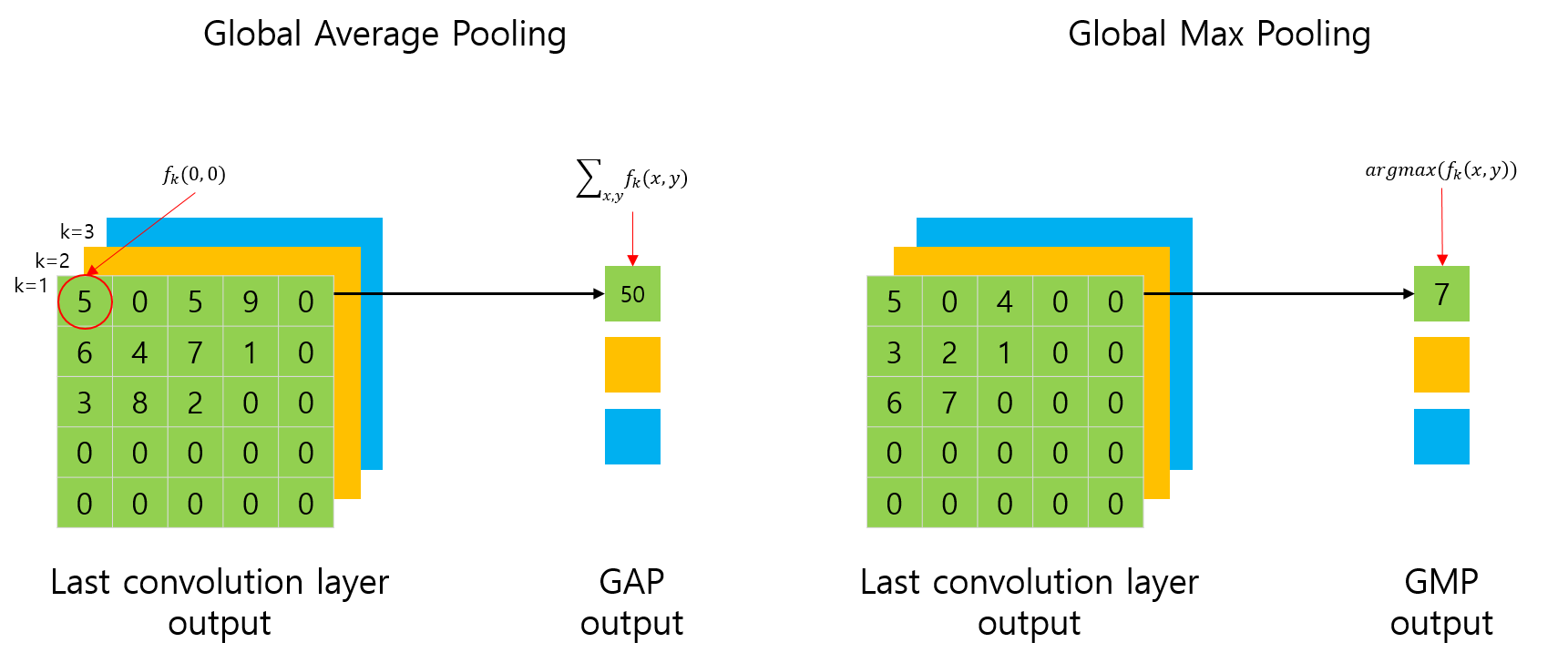
여기서 Z는 feature map에 포함된 요소의 합입니다. 위 그림의 예제에서는 25가 됩니다.
원래의 GAP 수식과 함께 다시 CAM을 구하는 수식을 살펴봅시다.
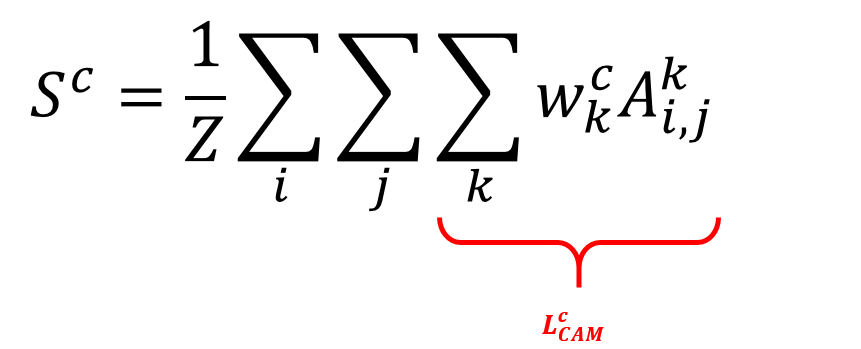
이전 포스트와 다른점은 \(f_k (x, y)\)가 \(A^k_{i, j}\) 로 표현되어있다는 점과, GAP의 원래 기능과 동일하게 \(1/Z\) 가 추가되었다는 것입니다. 이 수식을 다시 정리해서 표현해보면 다음 수식과 같습니다.
우리는 여기서 \(L^c_CAM\) 이라 표시된 부분이 CAM 이라는 것을 이전 포스트에서 이미 확인했었습니다. 그런데, 이 수식에 표시된 \(w^c_k\) 는 GAP layer 가 있어야 구할 수 있다는 단점이 있었죠.
Grad-CAM 에서는 이 weight를 gradient를 이용해서 구합니다.
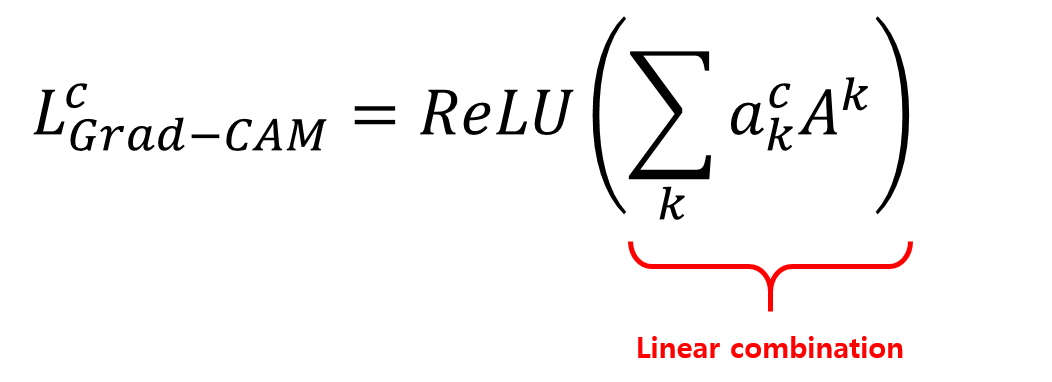
마지막으로 이전 포스트에서 CAM을 구할때와 유사하게 앞서 구해진 \(a_k^c\) 와 feature map \(A^k\) 간의 linear combination(weighted sum) 을 구하면 Grad-CAM을 구할 수 있습니다.
또한, Grad-CAM에선 추가로 linear combination 결과에 ReLU를 취합니다.
Grad-CAM 논문의 Appendix 에 있는 증명에 의하면, 다음 수식과 같이 \(Za^c_k = w^c_k\)와 동일합니다. 즉, Grad-CAM은 CAM을 일반화한 형태라고 볼 수 있습니다. 자세한 내용은 논문의 Appendix-Section A를 참고해보세요.
장황하게 소개했는데, 요약하자면 Grad-CAM은 CAM을 일반화시킨 것이며, gradient를 통해 weight를 구한다는 것입니다. gradient를 사용해서 weight를 구하기 때문에 CNN모델에 GAP가 포함되지 않아도 되고, 어떤 구조가 되어도 class-discriminative 한 Visualization이 가능합니다.
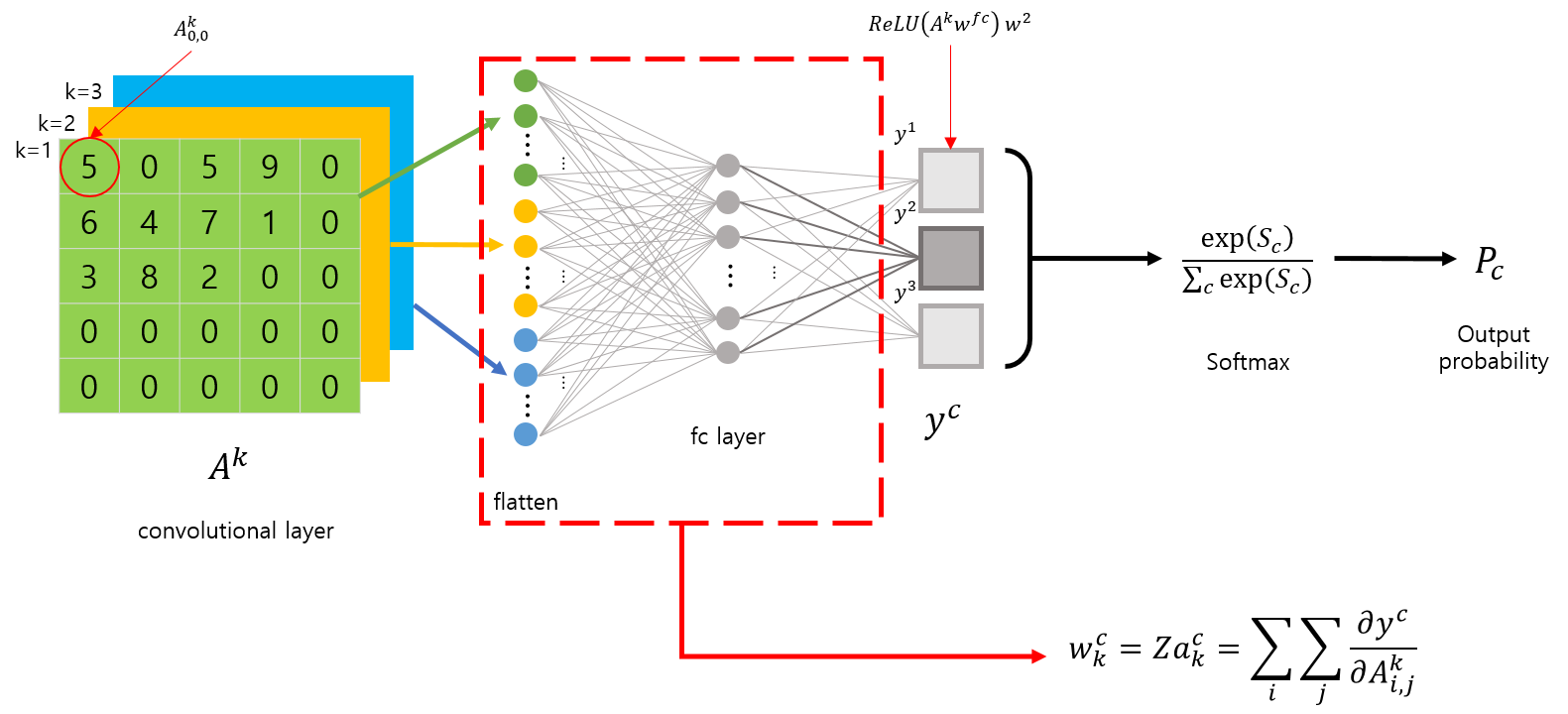
Grad-CAM with GAP layerGrad-CAM with FC layer
또 다른 장점은, 마지막 Convolution layer에 대한 시각화 뿐만 아니라, 중간에 위치한 특정 layer에 대한 시각화도 가능합니다. (gradient 를 사용하므로..)
What is Guided Grad-CAM
앞서 Grad-CAM논문에서는 Guided-Backpropagation과 Grad-CAM을 융합해서 class-discriminative 하면서 fine-grained importance 를 시각화하는 방법을 제안했다고 예기했습니다.
이 방법은, 먼저 Guided Backpropagation을 이용해서 saliency map을 구한 후, Grad-CAM과 saliency map의 크기를 bi-linear interpolation 을 사용해서 동일하게 맞춰준 후, 서로 곱하면됩니다.
본 포스트에서 다루는 Grad-CAM에 대한 소스코드는 [여기]를 참고하세요.
위 소스코드는 사용의 편의성을 위해서 class로 랩핑해뒀습니다.
그럼 어떻게 Grad-CAM을 구현하는지 알아볼까요?
구현 방법은 이전에 CAM 포스트에서 다뤘던 방법과 대부분 동일합니다. 이전에 구현했던 방법과 다른 점은 모델에서 weights를 가져오는 것이 아니라, gradient 를 계산해야 한다는 것이죠.
model_input=model.input# y_c : class_index에 해당하는 CNN 마지막 layer op(softmax, linear, ...)의 입력
y_c=model.outputs[0].op.inputs[0][0,class_index]# A_k: activation layer의 출력 feature map
A_k=model.get_layer(activation_layer).output# model의 입력에 대해서,
# activation conv layer의 출력(A_k)과
# 최종 layer activation 입력(y_c)의 A_k에 대한 gradient 계산
get_output=K.function([model_input],[A_k,K.gradients(y_c,A_k)[0]])[conv_output,grad_val]=get_output([img_tensor])# batch size가 포함되어 shape가 (1, width, height, k)이므로
# (width, height, k)로 shape 변경
# 여기서 width, height는 activation conv layer인 A_k feature map의 width와 height를 의미함
conv_output=conv_output[0]grad_val=grad_val[0]# global average pooling 연산
# gradient의 width, height에 대해 평균을 구해서(1/Z) weights(a^c_k) 계산
weights=np.mean(grad_val,axis=(0,1))# activation layer의 출력 feature map(conv_output)과
# class_index에 해당하는 gradient(a^c_k)를 k에 대응해서 linear combination 계산
# feature map(conv_output)의 (width, height)로 초기화
grad_cam=np.zeros(dtype=np.float32,shape=conv_output.shape[0:2])fork,winenumerate(weights):grad_cam+=w*conv_output[:,:,k]# 계산된 linear combination 에 ReLU 적용
grad_cam=np.maximum(grad_cam,0)
\(A_k\) 에 대한 gradient \(\frac{\partial y^c}{\partial A^k_{i,j}}\)는 ‘K.gradients(y_c, A_k)[0]’를 이용해서 구할 수 있습니다.
Guided Grad-CAM은 Guided-Backpropagation을 통해 얻은 saliency map을 곱하면 얻을 수 있습니다.
guided_gradcam=gradient*grad_cam[...,np.newaxis]
Results
몇가지 이미지에 대해 Grad-CAM과 Guided Grad-CAM을 출력한 결과는 다음 그림과 같습니다.
이 결과 이미지를 만드는 코드는 [keras-GradCAM]의 ‘Grad-CAM Visualization.ipynb’ jupyter notebook 파일을 참고하세요.
Results of Grad-CAM and Guided Grad-CAM
Source Code
References
[1] Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization, 2017 [paper]
[2] Learning Deep Features for Discriminative Localization, 2016 [paper][review]
[3] Striving for simplicity: The all convolutional net, 2014 [paper]
이 포스트에서는 2016년 CVPR에 실린 “Learning Deep Features for Discriminative Localization”의 Visualization 방법인 CAM(Class Activation Map)에 대해서 살펴보겠습니다.
Key Point
Weakly-supervised Learning for Object Localization
Visualize class discriminative features
2012년 ImageNet 데이터 셋을 이용한 대회인 ILSVRC에 CNN을 이용한 AlexNet이 우승한 이후, CNN에 대한 연구가 활발히 이루어지고 있습니다.
CNN의 발전 경향을 살펴보면 2012~2015년 사이에는 마지막 레이어로 Fully-connected layer를 사용하지만, 2015년 GoogLeNet에서 GAP(Global Average Pooling) layer를 사용한 이래로, 최근까지 등장하고 있는 새로운 CNN 아키텍쳐들은 마지막 layer에서 fc layer가 아닌 GAP layer를 사용하고 있습니다. 이유가 무엇일까요?
fc layer는 연산량 관점에서는 도입하기에 비용이 큰 layer 입니다. 말 그대로 Fully-connected 되어있기 때문에 Convolution layer와 비교해서도 당연히 연산에 필요한 파라미터가 많아 과적합(overfitting)되기 싶습니다.
또한, 논문 [2]에 따르면, CNN의 Convolutional unit들은 개체의 위치 정보를 보유하고 있지만, fc layer를 거침에 따라 이러한 위치 정보가 손실된다는 것을 확인했습니다.
이러한 fc layer의 여러가지 단점들을 해소하기 위해, 최근 등장하고 있는 CNN 아키텍처(GoogLeNet.2015, ResNet.2016, Xception. 2017 …)들은 마지막 layer로 fc layer대신 GAP layer를 사용하고 있습니다.
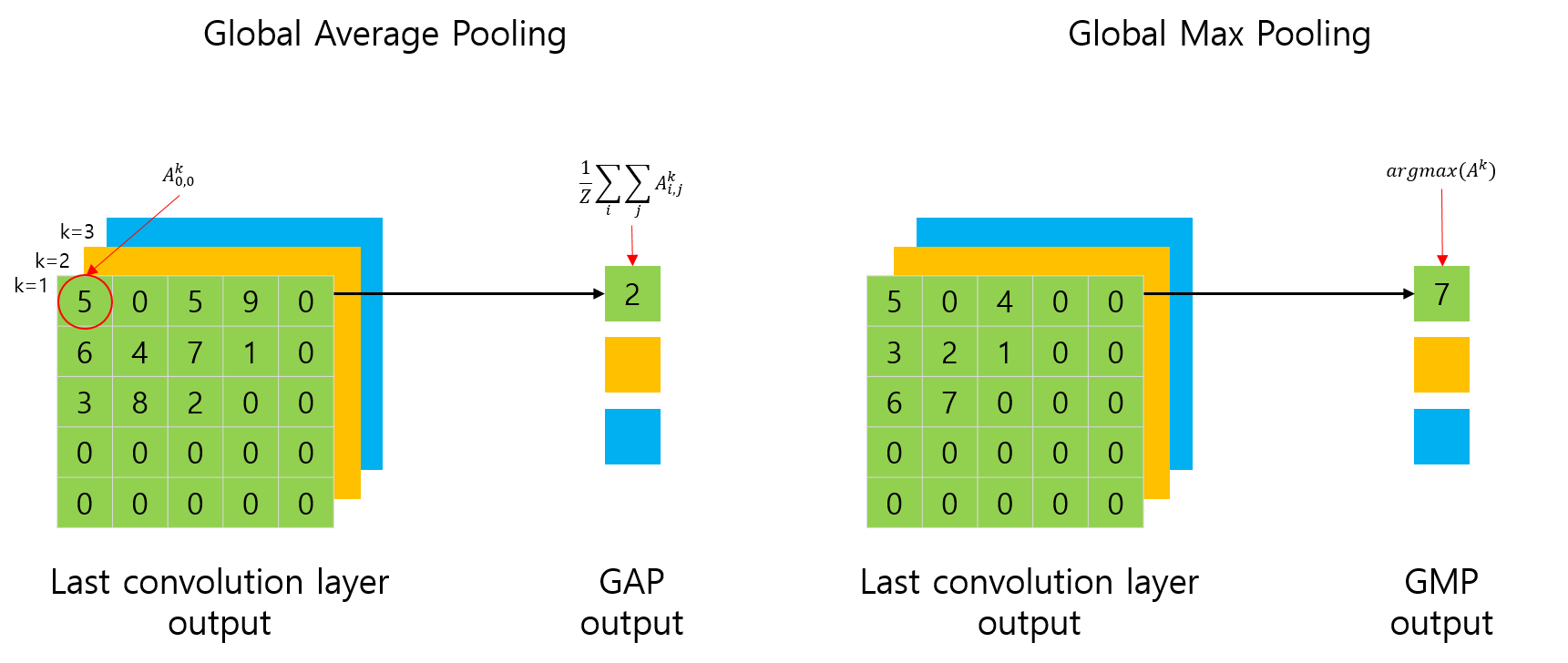
GAP(Global Average Pooling)와 GMP(Global Max Pooling)
그렇다면, GAP layer는 무엇일까요?
영문 이름에서 알 수 있듯이, 전역적으로(Global) Average Pooling을 수행하는 layer 입니다.
또한, 일반적인 pooling layer가 max 연산을 가지고 있듯이, GMP(Global Max Pooling)도 있습니다. 마찬가지로, 전역적으로 Max Pooling을 수행하는 layer를 의미합니다.
Global Average Pooling & Global Max Pooling
위 그림에서 좌측이 GAP를 표현한 그림이고, 우측이 GMP를 표현한 그림입니다.
사실, GAP 연산은 평균(Average)을 취해야 하는게 맞지만, 논문에서 표현한 수식과 혼동하지 않기 위해서 평균값을 취하지 않았습니다.
그림에서 표현된 것처럼 \(f_k(0,0)\)은 CNN의 feature map의 0,0 번째에 해당하는 요소의 값을 의미합니다.
GAP나 GMP의 연산 결과는 그림과 같이 각 채널별로 하나의 값이 나오게 됩니다. 즉, 이전 5x5 feature map의 채널이 3개였다면, feature map의 크기와 상관없이, 채널의 개수에 해당하는 3개의 값(1x1)이 출력됩니다. (당연한 말이죠? 전체에 대해 평균이나 최대값을 취했으니까요.)
이러한 GAP layer는 fc layer와 달리 연산이 필요한 파라미터 수를 크게 줄일 수 있으며, 결과적으로 regularizer와 유사한 동작을 해서 과적합을 방지할 수 있습니다.
fc layer에서는 Convolution layer에서 유지하던 위치 정보가 손실되는 반면, GAP나 GMP layer에서는 유지할 수 있습니다[2].
이번에 다루는 논문에서는 이러한 GAP와 GMP의 특성을 기반으로, 클래스에 따라 CNN이 주목하고 있는 영역이 어떤 부분인지 시각화하는 방법인 CAM(Class Activation Map) 제안하고 있으며, 이러한 시각화 방법은 Object Localization 으로도 활용될 수 있다고 합니다.
즉, 일반적인 Image Classification을 위해 Weakly-supervised로 학습된 CNN으로도 Image Localization을 할 수 있다는 의미입니다. 그럼 Class Activation Map이 무엇인지 살펴봅시다.
What is CAM(Class Activation Map)?
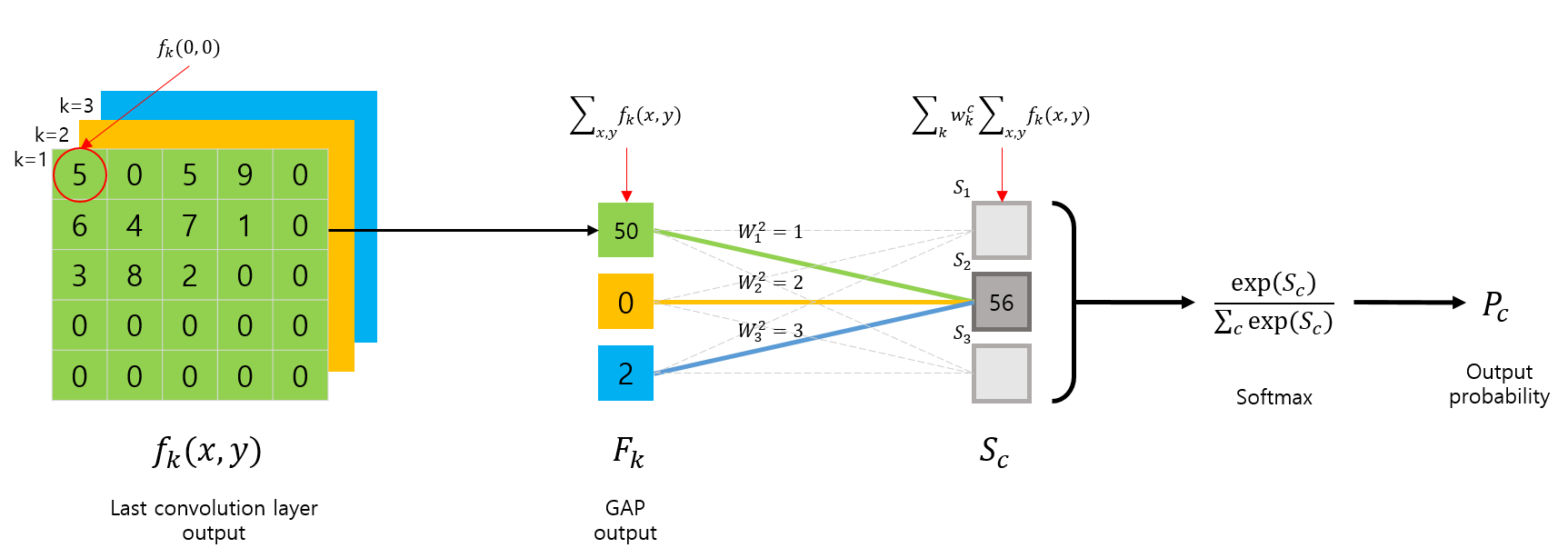
먼저 GAP를 사용하는 CNN 아키텍쳐의 구조를 살펴보면 다음 그림과 같이 요약할 수 있습니다.
CNN Architecture with GAP
먼저 마지막 Convolution layer 에서 출력된 feature map \(f_k(x,y)\) 는 GAP 연산이 취해지며 k개의 값이 출력됩니다.
\[F_k = \sum_{x,y}f_k(x,y)\]
이후 GAP의 출력은 CNN의 마지막 출력 layer인 \(S_c\) 로 전달되면서 linear combination(weighted sum)을 수행합니다.
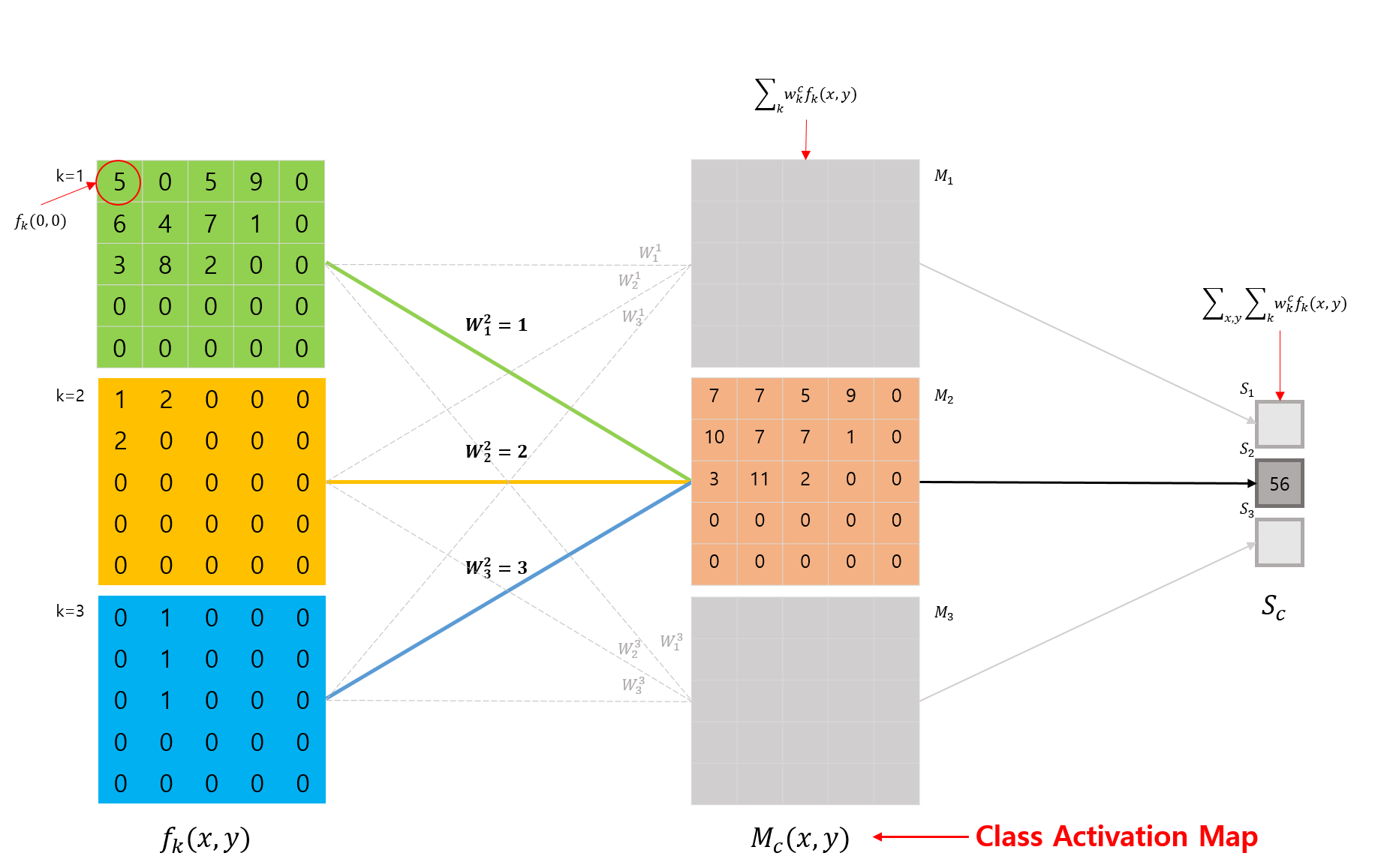
수식을 이해하기 위해 CAM이 어떤 동작을 하는지 다시한번 확인해봅시다.
CAM은 특정 클래스 \(c\) 를 구별하기위해 CNN이 어떤 영역을 주목하고 있는지 시각화하는 방법입니다.
2번째 그림(CNN Architecture with GAP)을 예로 들면,
특정 클래스 \(c = 2\) 를 구별하기 위해 이 클래스에 연결된 weights \(w^2_1, w^2_2, w^2_3\) 와 각 feature map에 대해 linear combination(weighted sum)을 취한 결과가 바로 CAM입니다.
3번째 그림(What is Class Activation Map)을 통해서 확인해보면, \(S_c\) 를 구하는 수식에서, GAP에 사용되었던 feature map에 대한 평균(논문에서는 합)만 제외한 것입니다. (당연히 feature map에 대해 합이나 평균을 취해버리면 시각화를 못하죠? 값이 하나가 되니까..)
이제 keras를 이용해서 CAM을 구현하는 방법에 대해 살펴봅시다.
How to implement CAM?
본 포스트에서 다루는 CAM에 대한 소스코드는 [여기]를 참고하세요.
위 소스코드는 사용의 편의성을 위해서 class로 랩핑해뒀습니다.
그럼 어떻게 CAM을 구현하는지 알아볼까요?
수식을 다시한번 가져와서 코드로 구현해봅시다.
수식을 살펴보면 \(f_k(x, y)\) 가 있습니다. \(f_k(x, y)\)는 마지막 Convolution layer 의 출력 feature map 입니다. 코드로 가져와 봅시다.
model_input=model.inputmodel_output=model.layers[-1].output# f_k(x, y) : 마지막 Convolution layer의 출력 feature map
f_k=model.get_layer(last_conv).output# model의 입력에 대한 마지막 conv layer의 출력(f_k) 계산
get_output=K.function([model_input],[f_k])[last_conv_output]=get_output([img_tensor])# batch size가 포함되어 shape가 (1, width, height, k)이므로
# (width, height, k)로 shape 변경
# 여기서 width, height는 마지막 conv layer인 f_k feature map의 width와 height를 의미함
last_conv_output=last_conv_output[0]
여기서 K.function은 keras.backend.function으로, placeholder tensor 리스트와, 모델 그래프내 특정 출력 tensor 리스트를 전달해주면 특정 layer의 출력들을 얻을 수 있는 함수를 반환해줍니다.
자, 우리는 지금 마지막 Convolution layer의 출력인 ‘last_conv_output’을 얻었습니다. 또 무엇이 필요할까요?
수식을 살펴보면 \(w_k^c\) 와의 linear combination(weighted sum) 이 필요하네요. 해당 클래스에 대한 weight들을 가져옵시다.
# 출력(+ softmax) layer와 GAP layer 사이의 weight matrix에서
# class_index에 해당하는 class_weight_k(w^c_k) 계산
# ex) w^2_1, w^2_2, w^2_3, ..., w^2_k
class_weight_k=model.layers[-1].get_weights()[0][:,class_index]
‘class_index’는 특정 클래스 \(c\) 를 의미합니다. 우리가 설정할수도 있고, 일반적으로는 모델이 예측한 클래스 인덱스를 사용합니다.
이제 feature map과 \(w_k^c\)에 대해 linear combination(weighted sum) 를 수행하는 코드를 구현해봅시다.
# 마지막 conv layer의 출력 feature map(last_conv_output)과
# class_index에 해당하는 class_weight_k(w^c_k)를 k에 대응해서 linear combination을 구함
# feature map(last_conv_output)의 (width, height)로 초기화
cam=np.zeros(dtype=np.float32,shape=last_conv_output.shape[0:2])fork,winenumerate(class_weight_k):cam+=w*last_conv_output[:,:,k]
CAM 구현이 다 끝났습니다.
하나만 참고할 점은, keras.backend.function() 함수는 모델 그래프 내 특정 레이어들의 출력을 얻기 위한 함수를 만들어준다고 했는데 이 작업은 꾀 시간이 걸리는 작업입니다. 따라서 여러개의 이미지에 대해 CAM을 얻어보고자 할 경우에는 keras.backend.function으로 함수를 만드는 작업을 분리하는게 좋습니다. class로 랩핑한 코드 [keras-CAM]를 참고해보세요.
자, 마지막으로 구현한 코드를 이용해서 cam을 얻어봅시다. 모델은 keras.application에 있는 ResNet50 모델을 사용했습니다.
※ CAM을 얻으려면 CNN의 마지막 Convolution layer와 모델의 출력 layer 사이에 fc layer가 아닌 GAP가 있어야 계산이 가능합니다.
※ 즉, VGG와 같은 아키텍쳐에서 사용하려면, fc layer 2개를 GAP로 대체한 후 다시 학습한 다음에 사용해야 합니다.
img_width=224img_height=224model=ResNet50(weights='imagenet')print(model.summary())img_path='../images/elephant.jpg'img=load_image(path=img_path,target_size=(img_width,img_height))preds=model.predict(img)predicted_class=preds.argmax(axis=1)[0]# decode the results into a list of tuples (class, description, probability)
# (one such list for each sample in the batch)
print("predicted top1 class:",predicted_class)print('Predicted:',decode_predictions(preds,top=1)[0])# Predicted: [(u'n02504013', u'Indian_elephant', 0.82658225), (u'n01871265', u'tusker', 0.1122357), (u'n02504458', u'African_elephant', 0.061040461)]
cam_generator=CAM(model,activation_layer)cam=cam_generator.generate(img,predicted_class)cam=cam/cam.max()cam=cam*255cam=cv2.resize(cam,(img_width,img_height))cam=np.uint8(cam)img=cv2.imread(img_path)img=cv2.resize(img,(img_width,img_height))cv_cam=cv2.applyColorMap(cam,cv2.COLORMAP_JET)fin=cv2.addWeighted(cv_cam,0.7,img,0.3,0)cv2.imshow('cam',cv_cam)cv2.imshow('image',img)cv2.imshow('cam on image',fin)cv2.waitKey()cv2.destroyAllWindows()
Results
몇가지 이미지에 대해 CAM을 출력한 결과는 다음 그림과 같습니다.
이 결과 이미지를 만드는 코드는 [keras-CAM]의 ‘CAM Visualization.ipynb’ jupyter notebook 파일을 참고하세요.
Results of CAM
Additional
지금까지 CAM이 무엇인지 그림과 수식을 통해 살펴보고, keras로 구현도 해봤습니다.
그런데, 마지막 출력 layer 이전에 fc layer를 포함하고 있는 VGG 아키텍쳐와 같이, GAP나 GMP layer가 위치하지 않으면 계산이 불가능하다는 단점이 있습니다.
다음에 살펴볼 논문인 Grad-CAM에서는 이러한 단점을 해결해서 모든 CNN 아키텍쳐에서 CAM을 출력할 수 있는 방법을 소개하고 있습니다.
Source Code
References
[1] Learning Deep Features for Discriminative Localization, 2016 [paper]
[2] Object detectors emerge in deep scene cnns [paper]
SSD(Single Shot MultiBox Detector) with Inception v3, Mobilenet, Resnet …
YOLO
…
이렇게 개발된 모델들은 각각의 상황에 따라 각기 다른 이점을 가지고 있습니다.
단편적인 예를 들자면, Inception Resnet v2를 feature extractor로 사용하는 Faster R-CNN은 정확도(accuracy) 측면에서 높은 성능을 보이지만, two way training/inference 구조의 한계로 속도가 느리다는 단점이 있습니다.
반면 R-FCN과 SDD는 Faster R-CNN보다는 약간 정확도가 떨어지지만 빠른 속도를 갖는 이점을 가지고 있습니다.
뿐만 아니라, 각 대회(Pascal VOC, COCO, …)의 데이터셋에 따라서도 성능이 상이합니다.
Tensorflow Object Detection API를 활용한 모델 학습하기 [원문 링크]
위에서 소개된 원문 링크에서는 Google Cloud환경에서 Oxford-IIIT Pets 데이터셋을 사용해서, resnet-101을 feature extractor로 사용하는 Faster R-CNN을 학습시키는 방법에 대해 소개하고 있습니다.
또한 Transfer Leraning을 위해 COCO-pretrained 모델을 사용하는 방법 또한 제시됩니다.
본 포스트에서는 위에서 소개된 원문 링크와는 달리, 로컬 컴퓨팅 환경에서 Pascal VOC 데이터셋을 이용해서 모델을 학습시키는 방법에 대해 살펴보겠습니다.
먼저 Object Detection 모델을 학습하기 위한 입력 데이터를 준비합니다.
Object Detection은 일반적인 Classification과 달리, 이미지내에 존재하는 개체들의 위치까지 식별해야 하는 작업이기 때문에, 학습데이터에는 개체의 위치에 해당하는 정보가 포함되어야 합니다.
Object Detection에 대한 간략한 소개는 Tensorflow Object Detection API를 참고해주세요.
개체의 위치에 대한 정보를 함께 제공하기 위해서,
개체를 둘러싸는 Bounding Box 좌측 상단(x, y)과 너비,높이(width, height) 혹은 좌측 상단(xmin, ymin)과 우측 하단(xmax, ymax)의 pixel위치 값을 해당 개체의 클래스와 함께
개체별로 Labeling해서 (annotation)파일로 작성합니다.
labeling된 annotation은 csv파일로 작성하거나, xml파일로 작성할 수 있습니다.
이번 포스트에서 학습 데이터로 사용할 Pascal VOC 데이터셋은 다음과 같은 xml파일로 annotation되어 있습니다.
Tensorflow Object Detection API에서는 모든 입력 데이터를 TFRecords로 변환해서 사용합니다. 따라서 다운로드받은 Pascal VOC 2012데이터셋을 TFRecords 파일로 변환해야 합니다.
다음의 create_pascal_tf_record.py Python 스크립트를 사용해서 Pascal VOC 2012 데이터를 TFRecords로 변환합시다.
** error fix **
- python 3.x의 경우, “FutureWarning: The behavior of this method will change in future versions. Use specific ‘len(elem)’ or ‘elem is not None’ test instead.” 에러 발생함
- python 2.x와 3.x간의 문법 변환에 따른 Warning이므로 무시해도 됨
label_map_path : 개체의 클래스 label을 맵핑해놓은 protobuf 파일의 경로(path)
data_dir : Pascal VOC 2012 데이터셋의 경로(path)
year : Pascal VOC의 경우 대표적으로 2007과 2012가 있으며, 이번 포스트에서는 2012를 사용하므로 VOC2012를 사용
set : 학습(train) / 검증(val) / 테스트(test) 셋 구분
output_path : 출력 파일 경로(임의)
앞서 모든 커멘드에 tensorflow/models/research/ 폴더에서 실행하라고 표현되어 있지만, 당연히 별도의 로컬 폴더를 생성하고, 다음과 같이 path를 지정해서 스크립트를 실행해도 괜찮습니다.
path/to/tensorflow/models/research/xxx.py
Pascal VOC 데이터셋이 아닌 COCO나 여타 다른 데이터셋의 형식으로 annotation되어 있을 경우, object_detection/dataset_tools폴더 에 포함된 create_xxxx_tf_record.py 파이썬 스크립트 파일을 사용합니다.
COCO dataset : create_coco_tf_record.py
kitti dataset : create_kitti_tf_record.py
oid dataset : create_oid_tf_record.py
pascal : create_pascal_tf_record.py
pet dataset : create_pet_tf_record.py
…
label_map 구성 또한 각 데이터셋별로 다르게 구성되어 있으며, object_detection/data폴더 에서 확인할 수 있습니다. pascal voc의 pascal_label_map.pbtxt은 다음과 같이 표현됩니다.
대부분의 Object Detection 모델들은 여러가지 데이터셋을 효과적으로 학습하거나, 식별하기 위한 모델 파라미터가 존재합니다.
예를들어 Faster R-CNN의 경우, 후보 영역을 제안하기 위한 RPN을 학습시키기 위해, anchor라는 개념이 도입되어 있는데, 이 anchor의 크기나 비율(aspect ratio)를 설정해주어야 합니다.
Tensorflow Object Detection API에서는 이러한 파라미터를 설정하는 것을 pipeline configuration이라 부르며, pipeline 또한 protobuf 파일로 구성합니다.
pipeline config 파일은 다음과 같이 5개의 part로 구분되어 있습니다.
model
사용하고자 하는 meta-architecture(Faster R-CNN? SSD?)와 feature extractor(resnet? inception?)
class의 개수
입력 이미지의 최소/최대 크기
anchor의 크기(scales)와 비율(aspect_ratios) 등
train_config
batch_size
사용하고자 하는 optimizer 및 learning rate scheduler 등
eval_config
검증을 위해 사용하고자 하는 metrics (pascal, coco, etc..)
train_input_config
학습시키고자 하는 입력 데이터 TFRecord 파일(앞서 준비한 학습 데이터 경로 - pascal_train.record)
label_map 정보
eval_input_config
검증하고자 하는 입력 데이터 TFRecord 파일(앞서 준비한 검증 데이터 경로 - pascal_val.record)
Object Detection 모델을 학습시키는 python 스크립트는 object_detection/model_main.py 파일입니다.
다음의 shell 커멘드를 사용해서 학습을 진행해봅시다.
# From the tensorflow/models/research/ directoryPIPELINE_CONFIG_PATH={path/to/models/pipeline config file}# 앞서 구성한 pipeline configuration 파일 경로MODEL_DIR={path/to/train}# 학습된 모델을 저장할 파일 경로NUM_TRAIN_STEPS=50000 # Training StepNUM_EVAL_STEPS=2000 # Eval Step
python object_detection/model_main.py \--pipeline_config_path=${PIPELINE_CONFIG_PATH}\--model_dir=${MODEL_DIR}\--num_train_steps=${NUM_TRAIN_STEPS}\--num_eval_steps=${NUM_EVAL_STEPS}\--alsologtostderr
여기서 NUM_TRAIN_STEP과 NUM_EVAL_STEP은 명확하게 확인이 안되어, 확인되는데로 다시 정리해두겠습니다.
앞의 커멘드를 입력하면 구성한 pipeline config파일을 참조해서 자동으로 Object Detection 모델을 학습하게됩니다.
** error fix **
- can’t pickle dict_values objects
- object_detection/model_lib.py - line 389에서 “category_index.values()”를 list(category_index.values())로 변경
학습의 경과는 TensorBoard를 이용해서 확인할 수 있습니다. 다음의 커멘드를 사용해서 경과를 확인합니다.
tensorboard --logdir=${MODEL_DIR}# path/to/train 위에서 지정한 모델 저장 경로
추가 사항
Faster R-CNN의 경우 4개 step으로 구성된 학습 단계가 있는데, 이 때, 1~2 step에서는 pre-trained model을 이용해서 RPN과 detection network를 각각 학습시킵니다.
만약 이 때, pre-trained model이 없으면, RPN이 재대로 학습되지 않고, RPN이 재대로 학습되지 않으면 이후 지역 제안 후보 영역(region proposal)을 재대로 생성하지 못해서 detection network로 학습이 안되는 문제가 발생합니다.
따라서, 본인의 domain에 맞는 feature extractor network를 미리 학습시키거나, imagenet과 같은 대규모 데이터셋으로 학습된 모델을 pre-trained model로 준비하여 적용하는 것이 좋습니다.
pre-trained model의 적용은 pipeline configuration 에서 train_config 항목의 fine_tune_checkpoint에 pre-trained model의 ckpt 파일 경로를 추가해주면 됩니다.
다음의 파일 내용을 참고해봅시다.
/object_detection/protos/train.proto
// Checkpoint to restore variables from. Typically used to load feature
// extractor variables trained outside of object detection.
optional string fine_tune_checkpoint = 7 [default=""];
// Type of checkpoint to restore variables from, e.g. 'classification' or
// 'detection'. Provides extensibility to from_detection_checkpoint.
// Typically used to load feature extractor variables from trained models.
optional string fine_tune_checkpoint_type = 22 [default=""];
train.proto 파일의 내용에 따르면,
만약 Faster R-CNN 자체를 학습시킨 모델을 pre-trained model로 사용하고자 한다면, fine_tuen_checkpoint에는 해당 모델의 경로를,
fine_tune_checkpoint_type에는 “detection” 이라는 type을 명시해줍니다.
만약 feature extractor를 pre-trained model로 사용하고자 한다면, fine_tuen_checkpoint에는 해당 모델의 경로를,
fine_tune_checkpoint_type에는 “classification” 이라는 type을 명시해줍니다.
여기까지 Tensorflow Object Detection API를 활용해서 모델을 학습하는 방법에 대해 살펴보았습니다.