
Paper Review - Grad-CAM
이 포스트에서는 2017년 ICCV에 실린 “Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization”의 Visualization 방법인 Grad-CAM에 대해서 살펴보겠습니다.
Key Point
- Weakly-supervised Learning for Object Localization
- Can apply almost all CNN Architectures
- Visualize more detailed class-discriminative feature(Guided Grad-CAM)
이전에 살펴본 CAM(Class Activation Map)논문 리뷰[2]에서는 CAM이 무엇인지 살펴보고 keras로 구현하는 방법에 대해서도 살펴보았습니다.
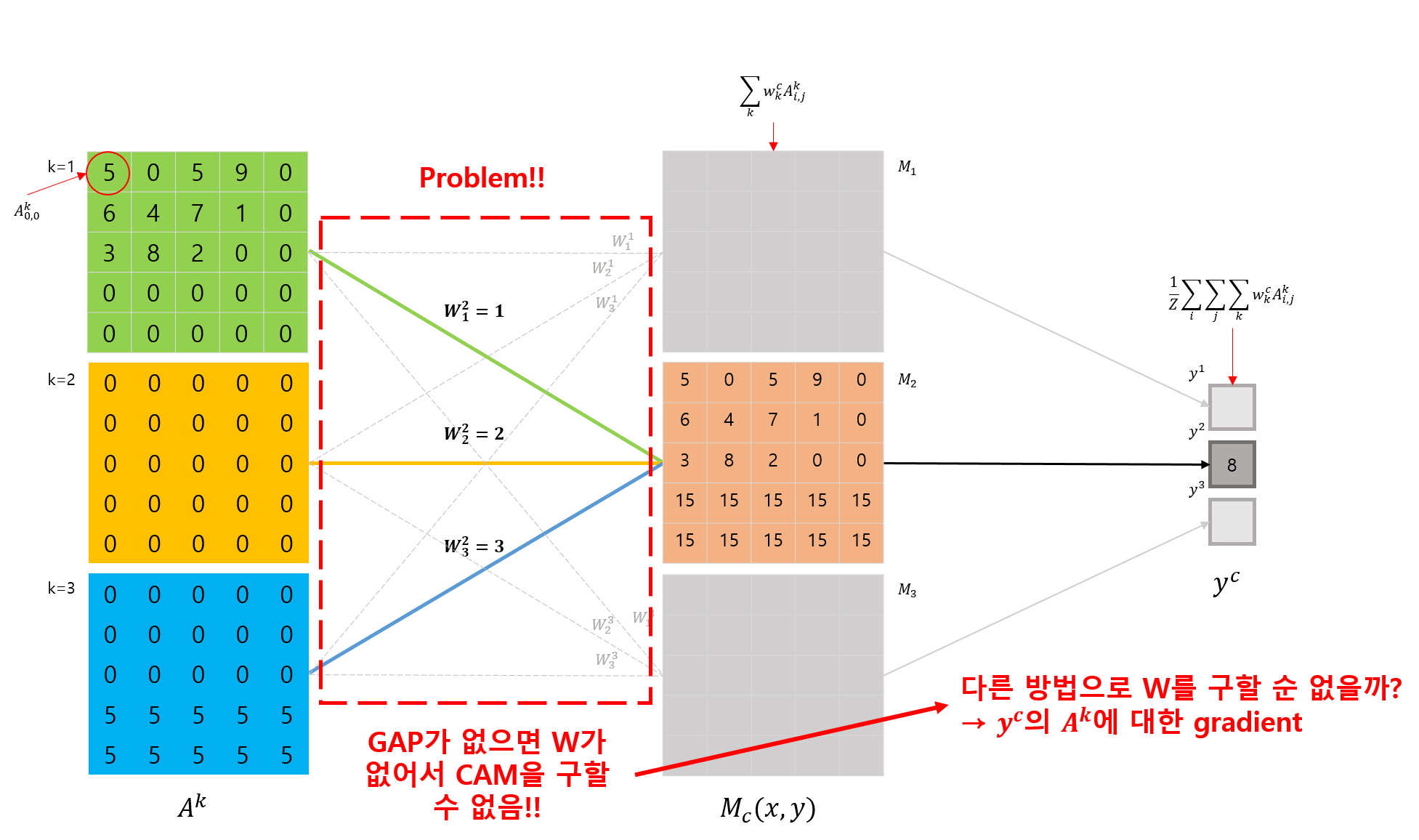
그런데, CAM은 모델의 출력 layer와 마지막 Convolution layer 사이에 무조건 GAP나 GMP layer가 위치해야 CAM을 얻기위한 연산이 가능하다는 큰 단점이 있었습니다.
이번 Grad-CAM[1] 논문에서는 이러한 단점을 해결해서 거의 모든 CNN 모델에 적용이 가능하다는 장점을 가지고 있습니다.
논문에서 Grad-CAM을 적용한 CNN 모델들은 다음과 같습니다.
- Fully-connected layer를 사용하는 CNN 모델
- Image Captioning과 같은 구조화된 출력을 사용하는 CNN 모델
- Multi-modal input을 사용하는 CNN(VQA)
- reinforcement learning
또한 Grad-CAM 논문에서는 Grad-CAM과 Guided Backpropagation 통해 얻은 pixel-space gradient와 같은 fine-grained importance를 융합해서 class-discriminative 하면서도, CNN이 주목하고 있는 세세한 부분을 시각화하는 방법을 제안하고 있습니다.
그럼 Grad-CAM이 무엇인지 살펴봅시다.
What is Grad-CAM
Grad-CAM과 CAM은 CNN모델이 GAP layer를 사용한다는 가정하에는 서로 동일한 동작을 합니다. 그런대 Grad-CAM은 CAM에서 GAP를 사용하는 단점을 해결한다고 언급했죠.
Grad-CAM에서는 GAP와의 연관성을 이용해서 CAM을 구하는 것이 아닌, gradient를 이용해서 CAM을 구한다는 차별점이 있습니다.
어떻게 Grad-CAM을 구하는지 알아보기에 앞서, GAP와 GMP에 대해 다시 살펴봅시다.
이전 포스트에서는 논문[2]에서 표현된 수식과의 혼동일 피하기위해 GAP를 합으로 표현했지만, 이번에는 원래 GAP의 수식대로 표현해봅시다.
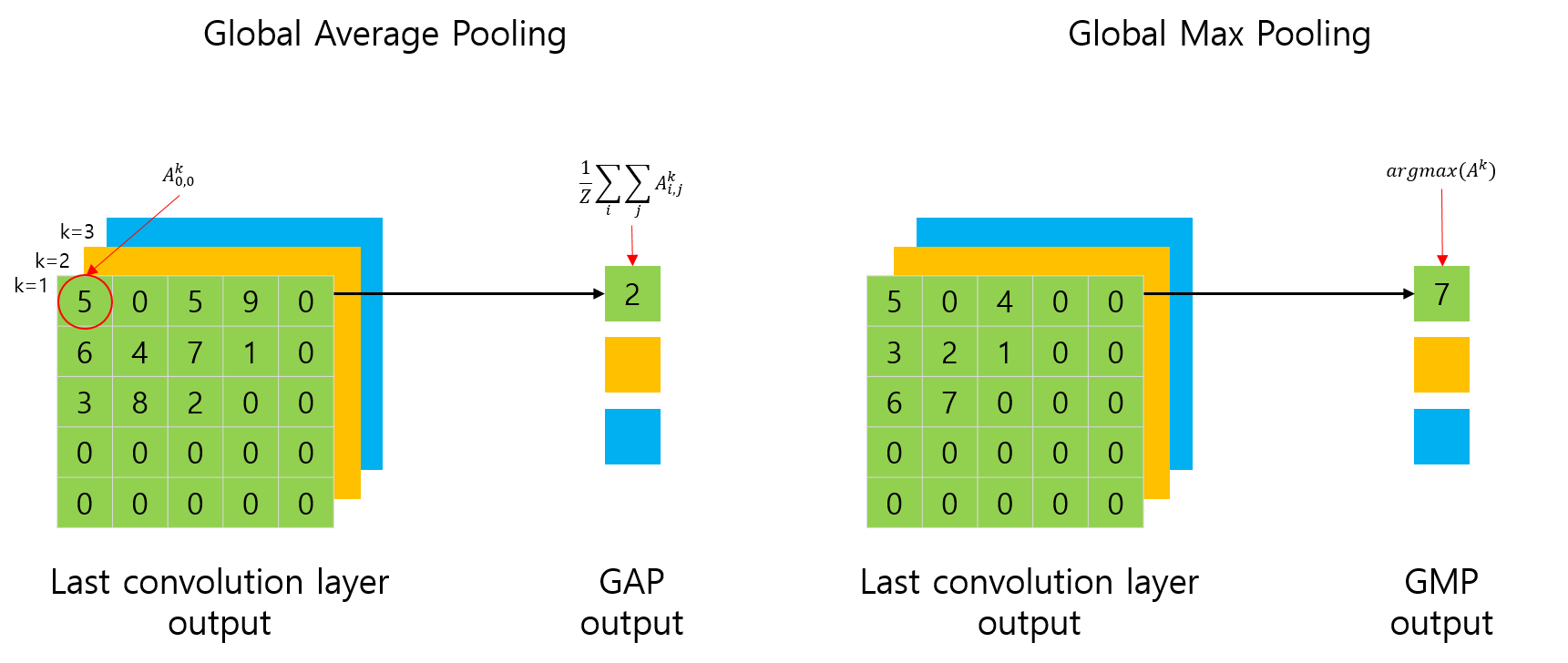
여기서 Z는 feature map에 포함된 요소의 합입니다. 위 그림의 예제에서는 25가 됩니다.
원래의 GAP 수식과 함께 다시 CAM을 구하는 수식을 살펴봅시다.

이전 포스트와 다른점은 \(f_k (x, y)\)가 \(A^k_{i, j}\) 로 표현되어있다는 점과, GAP의 원래 기능과 동일하게 \(1/Z\) 가 추가되었다는 것입니다. 이 수식을 다시 정리해서 표현해보면 다음 수식과 같습니다.
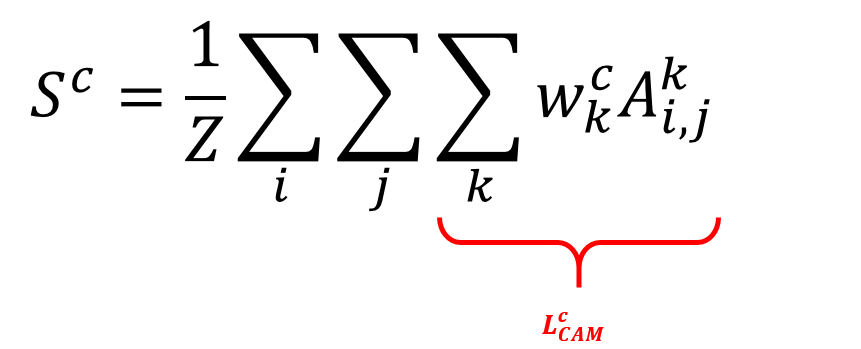
우리는 여기서 \(L^c_CAM\) 이라 표시된 부분이 CAM 이라는 것을 이전 포스트에서 이미 확인했었습니다. 그런데, 이 수식에 표시된 \(w^c_k\) 는 GAP layer 가 있어야 구할 수 있다는 단점이 있었죠.
Grad-CAM 에서는 이 weight를 gradient를 이용해서 구합니다.
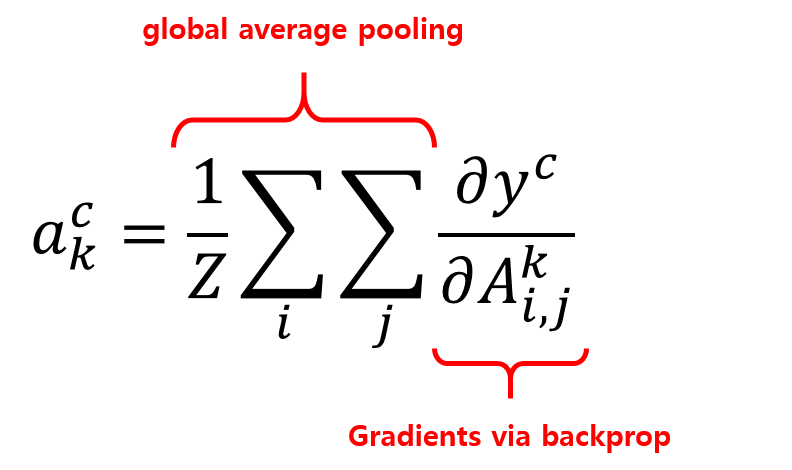
마지막으로 이전 포스트에서 CAM을 구할때와 유사하게 앞서 구해진 \(a_k^c\) 와 feature map \(A^k\) 간의 linear combination(weighted sum) 을 구하면 Grad-CAM을 구할 수 있습니다.
또한, Grad-CAM에선 추가로 linear combination 결과에 ReLU를 취합니다.
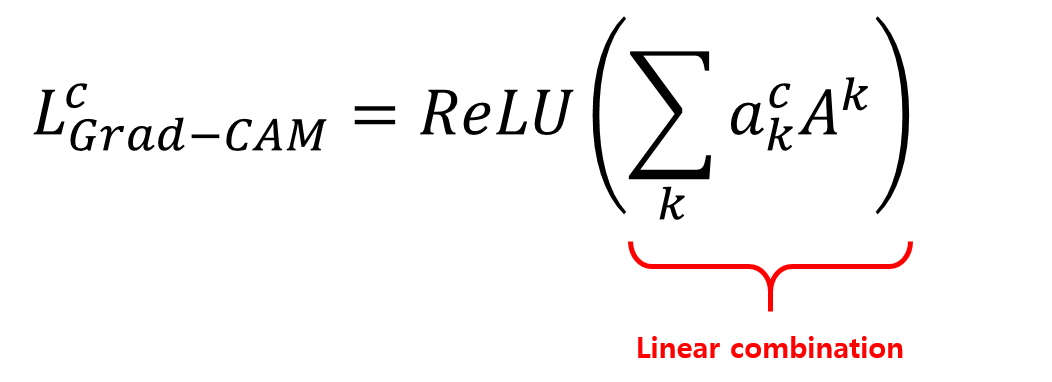
Grad-CAM 논문의 Appendix 에 있는 증명에 의하면, 다음 수식과 같이 \(Za^c_k = w^c_k\)와 동일합니다. 즉, Grad-CAM은 CAM을 일반화한 형태라고 볼 수 있습니다. 자세한 내용은 논문의 Appendix-Section A를 참고해보세요.
\[w^c_k = Za^c_k = \sum_i\sum_j\frac{\partial y^c}{\partial A^k_{i,j}}\]장황하게 소개했는데, 요약하자면 Grad-CAM은 CAM을 일반화시킨 것이며, gradient를 통해 weight를 구한다는 것입니다. gradient를 사용해서 weight를 구하기 때문에 CNN모델에 GAP가 포함되지 않아도 되고, 어떤 구조가 되어도 class-discriminative 한 Visualization이 가능합니다.
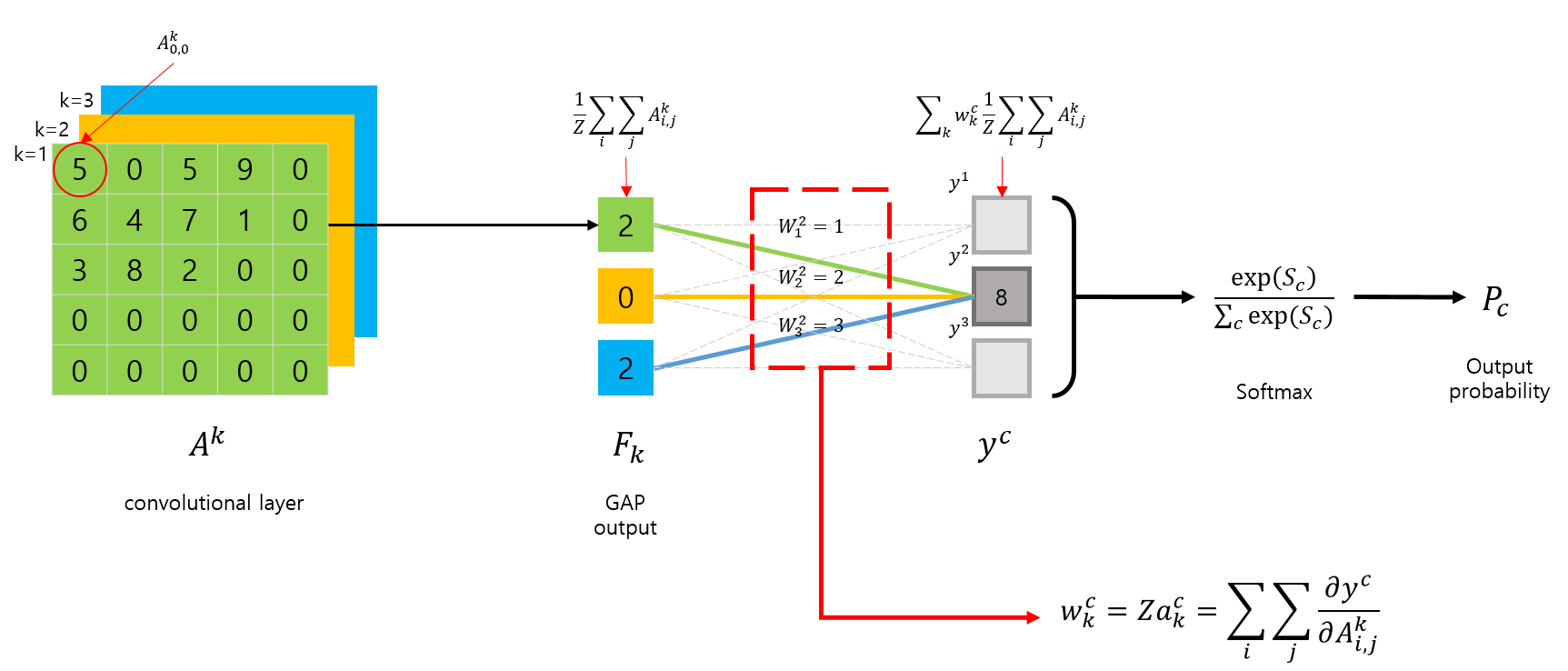
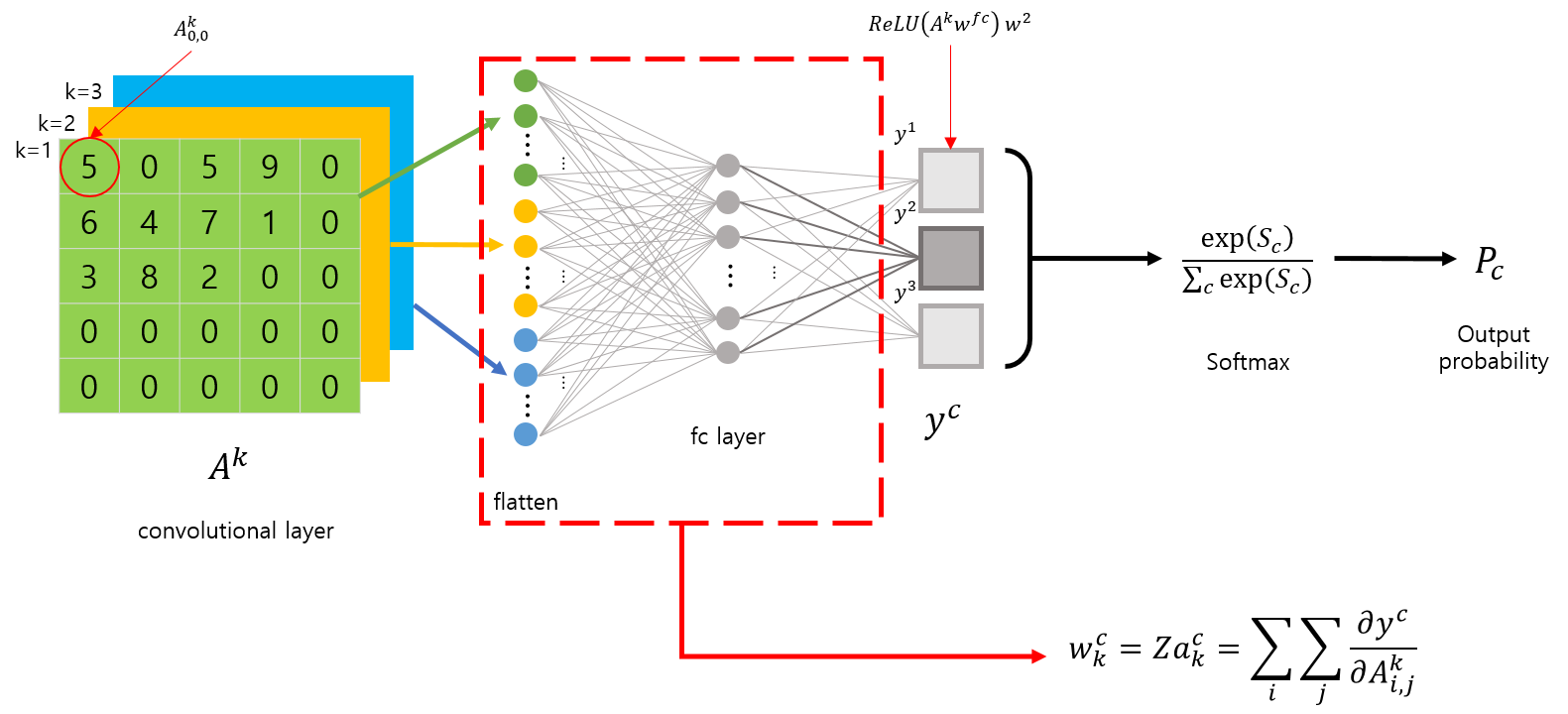
또 다른 장점은, 마지막 Convolution layer에 대한 시각화 뿐만 아니라, 중간에 위치한 특정 layer에 대한 시각화도 가능합니다. (gradient 를 사용하므로..)
What is Guided Grad-CAM
앞서 Grad-CAM논문에서는 Guided-Backpropagation과 Grad-CAM을 융합해서 class-discriminative 하면서 fine-grained importance 를 시각화하는 방법을 제안했다고 예기했습니다. 이 방법은, 먼저 Guided Backpropagation을 이용해서 saliency map을 구한 후, Grad-CAM과 saliency map의 크기를 bi-linear interpolation 을 사용해서 동일하게 맞춰준 후, 서로 곱하면됩니다.
Guided-Backpropagation 은 논문 [3] 에서 제안한 내용입니다. 자세한 내용은 논문과 “Paper Review - All Convolutional Net” 포스트를 참고해주세요.
How to implement Grad-CAM?
본 포스트에서 다루는 Grad-CAM에 대한 소스코드는 [여기]를 참고하세요.
위 소스코드는 사용의 편의성을 위해서 class로 랩핑해뒀습니다.
그럼 어떻게 Grad-CAM을 구현하는지 알아볼까요?
구현 방법은 이전에 CAM 포스트에서 다뤘던 방법과 대부분 동일합니다. 이전에 구현했던 방법과 다른 점은 모델에서 weights를 가져오는 것이 아니라, gradient 를 계산해야 한다는 것이죠.
model_input = model.input
# y_c : class_index에 해당하는 CNN 마지막 layer op(softmax, linear, ...)의 입력
y_c = model.outputs[0].op.inputs[0][0, class_index]
# A_k: activation layer의 출력 feature map
A_k = model.get_layer(activation_layer).output
# model의 입력에 대해서,
# activation conv layer의 출력(A_k)과
# 최종 layer activation 입력(y_c)의 A_k에 대한 gradient 계산
get_output = K.function([model_input], [A_k, K.gradients(y_c, A_k)[0]])
[conv_output, grad_val] = get_output([img_tensor])
# batch size가 포함되어 shape가 (1, width, height, k)이므로
# (width, height, k)로 shape 변경
# 여기서 width, height는 activation conv layer인 A_k feature map의 width와 height를 의미함
conv_output = conv_output[0]
grad_val = grad_val[0]
# global average pooling 연산
# gradient의 width, height에 대해 평균을 구해서(1/Z) weights(a^c_k) 계산
weights = np.mean(grad_val, axis=(0, 1))
# activation layer의 출력 feature map(conv_output)과
# class_index에 해당하는 gradient(a^c_k)를 k에 대응해서 linear combination 계산
# feature map(conv_output)의 (width, height)로 초기화
grad_cam = np.zeros(dtype=np.float32, shape=conv_output.shape[0:2])
for k, w in enumerate(weights):
grad_cam += w * conv_output[:, :, k]
# 계산된 linear combination 에 ReLU 적용
grad_cam = np.maximum(grad_cam, 0)
\(A_k\) 에 대한 gradient \(\frac{\partial y^c}{\partial A^k_{i,j}}\)는 ‘K.gradients(y_c, A_k)[0]’를 이용해서 구할 수 있습니다.
Guided Grad-CAM은 Guided-Backpropagation을 통해 얻은 saliency map을 곱하면 얻을 수 있습니다.
guided_gradcam = gradient * grad_cam[..., np.newaxis]
Results
몇가지 이미지에 대해 Grad-CAM과 Guided Grad-CAM을 출력한 결과는 다음 그림과 같습니다. 이 결과 이미지를 만드는 코드는 [keras-GradCAM]의 ‘Grad-CAM Visualization.ipynb’ jupyter notebook 파일을 참고하세요.

Source Code
References
[1] Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization, 2017 [paper]
[2] Learning Deep Features for Discriminative Localization, 2016 [paper] [review]
[3] Striving for simplicity: The all convolutional net, 2014 [paper]